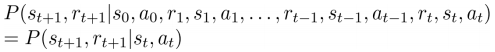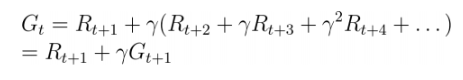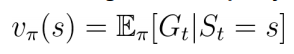※ 상태 전이(state transition) : 한 상태에서 다른 상태로 (의사결정 없이 자연스럽게) 넘어가는 행위
◆ Stochastic Control
확률적으로 의사 결정
◆ 행동 확률 vs 상태 전이 확률
ㆍ행동 확률
내가 행동할 확률
오목에서, 내가 흑돌을 놓을 확률
ㆍ상태 전이 확률
(내 행동에 이어) 상태가 바뀔 확률
내가 흑돌을 놓은 후 상대가 백돌을 놓을 위치의 확률(놓는 위치에 따라 상태 바뀜)
Q1) 내가 흑돌을 놓으면, '내가 흑돌을 놓은 상태'가 되는데 이건 상태 전이가 아닌가? Q2) 동전 던지기에서 동전 던지는 게 행동이고, 그 결과로 앞/뒷면이 나오는 게 상태 전이라면, 행동 확률은 '동전을 던질 확률'인가? 그럼 안 던질 수도 있는건가?
◆ 강화학습의 기본적인 개념
① Agent가 나름의 규칙으로 행동을 결정한다. ② Agent의 행동에 따라 상태가 전이 된다. ③ 전이된 상태에서의 보상을 agent에게 준다. ④ Agent는 보상에 따라 자신의 규칙을 수정한다.
ㆍ규칙(Policy)
Agent가 행동을 결정하는 규칙
ㆍ보상(Reward)
Agent에게 주는 보상(쾌락)
◆ Markov property (마르코프 성질)
미래 상태로의 변화가 과거 상태와는 독립적으로현재 상태에 의해서만 결정된다!
과거 상태를 전부 고려하는 것과, 오로지 현재 상태만 고려하는 것이 동일한 확률이라는 것. 다른 의미로, 과거를 잊어버려 memoryless 한 성질이라 함.
하지만, 현실의 모든 문제가 markov property 를 만족하지는 않는다. 따라서, 근사하게라도 state 가 markov property 를 띄도록 시간적 의미를 state 에 넣는 경우가 많음.
(여러 프레임을 넣거나, 속/가속도 등의 시간 속성이 포함된 정보를 state 에 포함시키는 방식을 취함.)
◆ Markov Decision Process (MDP)
강화학습의 기본 구성 요소를 수식적으로 설명한 모델
<S, A, P, R, γ>로 정의된다.
=> S – A – R – S’ 가 이어지는 구조!
MDP는MarcovProperty를 기반으로 고안된 모델이다.
MDP란 강화학습에서 환경이 모두 관측가능한 상황을 의미한다.
거의 모든 강화학습 문제들은MDP형태로 만들어 풀 수 있다.
ㆍState 𝑆𝑡
Agent의 t시점의 상태나 얻은 정보
ㆍReward 𝑅𝑡
Agent가 t-1 시점의 action으로 받은 보상
ㆍAction 𝐴𝑡
Agent가 t시점에 한 행동
◆ Stochastic Policy
수행할 action을 확률로 나타낸 Policy
MDP에서 요 녀석을 사용함
ex)
Policy 𝜋(𝑎|𝑠) ∶ 𝑆, 𝐴 → [0, 1]
: state s 와 action a 를 input 으로 받아, 해당 action a 를 state s 에서 행할 확률을 나타내는 조건부 확률 함수
◆ Model-based vs Model-free
MDP를 모른다 == Agent가 환경을 제대로 모른다. == 보상 함수와 전이 확률을 모른다.
ㆍModel-based 알고리즘
MDP를 아는 상황에 적용하는 알고리즘
ㆍModel-free 알고리즘
MDP를 완전히 모르는 문제에 적용하는 알고리즘
현실의 문제는 대부분 model-free이고, 따라서 우리도 model-free 알고리즘을 위주로 볼 것임!
◆ Model-free 알고리즘
전이 확률을 모르는 상태에서 그것을 확률적으로 근사해 알아내는 방법
◆ MDP의 dynamic function (혹은 dynamics)
state s 에서 어떤 action a 를 했을 때, 다음 state 인 state s’ 가 되고 reward r을 받을 확률을 다음과 같이 정의한다.
이 확률을 상태 전이 확률(Transition Probabilities) 혹은 상태 전이 함수(Transition Probability function)라고 부른다.
◆ (MDP로 정의된 문제에서) 강화학습의 목적
장기적인 보상을 최대화하는 최적의 policy를 찾는 것
지금까지 언급했던 보상은 행동에 대해 하나씩 주던 단기적 보상임.
장기적 보상은 agent가 활동의 시작부터 끝까지 받은 보상의 총합. 이것을 '이득'이라고 부름
ㆍReturn(이득) 𝑮𝒕
agent가 활동의 시작부터 끝까지 받은 보상의 총합.
현재 시점에서 이득은, 현재 시점에서 에피소드 끝날 때까지 받은 장기적인 보상
다시말해!!
강화학습의 목적은 Expected Return을 Maximize하는 것
이에 따른 우리의 목표는,
Expected Return을Maximize하는action을 내놓는Optimal Policy를 찾는 것이 되겠다.
•Optimal Policy는 상태가치함수V(st)를Maximize하는Policy
•상태가치함수란 현재State로부터 기대되는Return을 의미한다.
◆그럼 Optimal Policy를 어떻게 찾는가?
미래에 대한 Optimal 행동가치함수 Q*가 주어져 있다고 하면, 현재의 Q값을 Maximize하는 Optimal Policy는 찾기 쉬워진다.
◆ 그럼 Q*를 어떻게 얻는가?
트레이닝을 통해 Q*에 다가가기 위해서는 다음 두 가지 방법을 사용할 수 있다.
1) Monte Carlo method (MC) 2) Temporal Difference method (TD)
◆ MC vs TD
1) bias 측면
MC는,unbiased하다는 장점.
TD는,biased하다는 단점.
2) various 측면
MC는,various가 엄청 크다는 단점.
엄청 많이 돌아다닌 상태와 바로 다음 상태가 똑같을 수도 있는 것.너무 다채롭게 나옴.
TD는,바로 다음 것만 보기 때문에various가 크지 않다는 장점
◆ 이득에 관한 수식
ㆍ에피소드
Agent의 초기 상태부터 종결 상태까지의 과정
에피소드의 종결 == 종결 상태에 도달했다!
이 식은 시점t부터 agent 가종결 상태(terminal state) 에 도착한 종결 시점T까지, 시행착오를 통해 agent 가 실제로 얻은 보상을 전부 더한 것이다.
그런데, T가 무한대인 경우
agent가 최대화하려는 이득이 수식적으로 무한대가 되고
미래 보상과 현재 보상이 다 더해지기만 해서 둘의 차이를 반영하지 않기 때문에
이 식을 사용하기 어려운 경우가 많음.
◆ 이득에 관한 수식 - 감가율
따라서, 위 식과 같이 미래의 보상에 대한 discount rate 𝜸 (감가율, [0, 1]) 를 step 마다 곱해주어, 미래의 보상에 대한 패널티를 준다. 이 감가율을 통해 위 무한 급수는 유한한 값으로 비로소 수렴하게 된다.
이 식에서는 미래 보상과 현재 보상 간의 차이를 아래와 같이 확인할 수 있다.
위 식과 같이 재귀적으로 표현할 수도 있음! 이득은 결국 종결 시점 후에야 이전 시점의 이득을 계산할 수 있음. 위 식의 형태를 이용하면 종결될 때까지 시점의 보상을 모두 저장해두고, 에피소드가 끝나면 뒤에서부터 저장한 보상을 하나씩 더해가며 맨 처음 시점까지 이어지는 과정 중의 모든 시점의 이득을 순서대로 계산해 나갈 수 있다.
이득은 어떤 state s에서 실제 시행착오를 수행해 agent 가 얻을 수 있는 보상 중 하나의 샘플(예시) 데이터를 추출한 것으로 보면 된다.
◆ 벨만 방정식
• 벨만 방정식은 Value Function들을 관장하는 방정식이라 볼 수 있다.
벨만 방정식을 이용해 MDP에서 Value Function을 풀 수 있다.
• V(s)와 V(s+1),Q(s)와 Q(s+1)의 관계를 설명한 것이다.
• 벨만 방정식에 의해, s에서의 상태 가치함수V(st)=E[Rt+1+γV(St+1)|St=s]라 할 수 있다.
◆ 상태 가치 함수 (State Value Function)
어떤 상태 𝐬의 가치를 내놓는 함수 𝒗(𝐬)
ㆍ가치(value)
어떤 상태가 얼마나 좋은 상태인지, 그 상태가 가지는 값어치. 상태가 가질 수 있는 return 𝐺𝑡들의 기댓값
그냥 return𝐺𝑡는 특정 에피소드에 관해서만의 관측값이므로, 상태 자체의 가치를 정의할 때는 이것들의 평균을 사용함.
위의 정의는 만일 agent 가 state s 에서 탐험을 시작할 경우, 평균적으로 𝒗(𝐬) 만큼의 감가율이 적용된 reward 을 받을 거란 의미
여기다 policy의 개념까지 추가한 것이 아래 식임.
즉, policy 𝜋를 따를 때, 각 상태가 가지는 이득의 평균
◆ 몬테카를로 방식
반복된 무작위 샘플링으로 함수의 값을 수리적으로 근사하려는 방식
현재 상태의 가치를 나타내는 가치 함수의 참값을 정확하게 나타내기 위해서는, 큰수의 법칙을 따라 예상되는 모든 return 의 기댓값(평균)으로써 가치 함수를 정의하는 것이다. (통계적 언어로는 Gt 를 vt의 불편 추정량이라 한다.)
이런 기댓값 방식은 상태의 가치를 알아내려는 것 뿐만 아니라, MDP의 알지 못 하는 요소를 근사해서 학습에 사용하는 model-free 강화학습의 근간이 됨!!
◆ 행동 가치 함수 (State-Action Value Function)
어떤 행동 a의 가치를 내놓는 함수
상태 가치 함수의 행동 버전.
행동에 대한 return들의 기댓값 즉, 어떤 상황 s에서 어떤 행동 a를 했을 때의 이득의 평균
◆ 정책의 비교
가치 함수의 값을 크게 하는 policy == 장기적인 보상을 더 크게 하는 policy == 좋은 policy
가치 함수를 통해 상태나 행동을 비교할 수도 있지만, 어떤 정책이 더 좋은 정책인지 비교할 수도 있음!
모든 state 𝒔 ∈ 𝑺 에서 상태 가치 함수 𝒗(𝝅) ≤ 𝒗(𝝅′) 일 때, 𝝅′ 가 𝝅 보다 더 좋은 policy 라고 정의한다.
결론적으로 우리는, policy의 가치 함수를 최대화해야 함!
즉, 젤 좋은 policy를 만들어야 함.
◆ Q Learning
• Q-Learning에서는 Greedy action을 하며 Q값을 업데이트 한다. 이때 입실론-Greedy를 사용한다.
• 0~1사이의 값인 입실론 값을 통해, Exploration을 할지 Exploitation을 할지 결정한다.
• Exploration은 Greedy하게 가는 것이 아니라 랜덤하게 탐험하는 것이고, Exploitation은 지금껏 알아낸 Q 정보를 이용해 Greedy하게 움직이는 것을 의미한다.
• 처음에는 주로 입실론 값을 크게 주고, 점점 입실론을 0으로 decaying해 나간다. 즉 처음에는 Exploration 위주로, 학습을 할수록 Exploitation 위주로 진행하도록 한다.
◆ 카트폴 실습 (Python)
• State: cart position, cart velocity, pole angle, pole angular velocity
• Action: 왼쪽(0), 오른쪽(1)
• Reward: 모든 증가하는 timestep에 대해 +1
• 막대가 너무 멀리 떨어지거나, 카트가 중심으로부터 2.4 유닛보다 멀리 이동한다면 종료
• 즉, 오랜 시간동안 종료되지 않는 시나리오가 큰 리턴값을 줌!
• 입실론-Greedy 에 따라 exploration/exploitation행동 선택. (select_action)
• 무작위로 샘플링할 때 Transition을 ReplayMemory로 저장하고 재사용함.
• TD방식의 오차를 줄이기 위해,Huber loss 계산해서 손실이 기준치 이하인 경우만 반영