
센로그
6. Synchronization Tools 본문
◆ Synchronization
프로세스들은 concurrently하게 실행된다.
인터럽트가 언제든지 발생할 수 있으므로, 한번에 끝까지 실행되는 경우는 별로 없다.
그런데 concurrent하게 동작하는 여러 스레드가 공유 메모리에 있는 하나 데이터에 접근하면, 누가 먼저 접근하느냐에 따라 결과 값이 매번 달라질 것이다. (Race Condition)
따라서 이런 경우 일관성이 보장되도록 동기화해주는 작업이 필요하다.
◆ Race Condition
프로그램을 실행한 결과가 deterministic하지 않고,
각각의 instruction들의 실행되는 순서에 따라서 바뀌는 경우를 race condition이 있다고 한다.
여러 개의 스레드 데이터가 레이싱을 하고있는데
스레드의 상대적인 속도(실행 순서)에 따라서 값이 달라지는 경우에 race condition이 있다고 한다.
race condition은 정확한 결과를 필요로 하는 시스템에 매우 치명적이다.
따라서 Synchronization(동기화) 작업을 통해 스레드들의 메모리 접근을 적절하게 조절해줘야 한다.
ex)
공유 메모리에 저장된 k를 읽어와 +=1을 한 후 저장하는 코드를 스레드1, 스레드2가 있다고 하자.

k 의 초기값을 1이라 하자. 이때 스레드들의 속도에 따라 결과값이 달라진다.
결과 1) 만약 스레드1이 굉장히 빨리 달리면, 스레드2가 도달하기 전에 동작을 다 끝내버릴 수 있을 것임.
스레드 1을 끝내면 k=2가 됨.
그러면 스레드2는 스레드1에서 바꿔놓은 k를 읽어와서, +=1하고 저장함.
결과적으로 k=3이 됨.
결과 2) 만약 스레드1과 스레드 2의 속도가 비슷하다고 하자. 그러면 스레드1이 로드하고, 스레드2가 로드하고, 각각 번갈아가며 +=1해서 저장하는 경우가 될 것. 스레드1이 load하는 시점의 k =1 이고, 스레드2가 load하는 시점의 k =1이라, 각각 하나씩 올리고 저장하면 결과적으로 k=2가 됨.
◆ Critical Section
race condition을 발생시킬 수 있는 코드 부분을 의미한다.
동기화 문제가 발생할 수 있는 코드(critical section)는 보호해줘야 한다.
critical section에 여러 스레드가 동시에 들어가지 못하도록 해주면 race condition을 막을 수 있다.
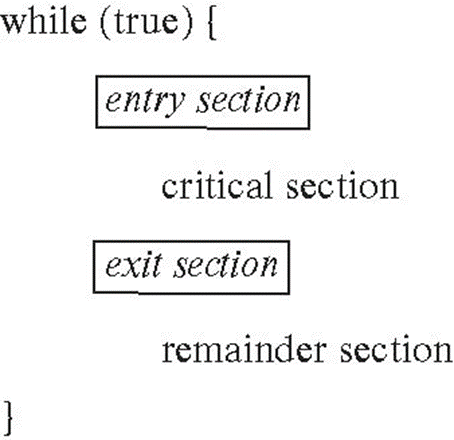
P1이 entry section을 통해 critical section에 진입하면, 중간에 P2는 들어갈 수 없음.
P1이 작업 다 끝내고 Critical section exit! 하면 그제서야 P2가 들어갈 수 있게 된다.
◆ 동기화 문제를 해결하기 위한 세 가지 조건
Critical Section을 보호하기 위한 세 가지 조건
1. Mutual Exclusion
- critical section을 실행하는 스레드는 무조건 하나여야 한다.
(한 스레드가 critical section을 실행하고 있으면, 다른 프로세스는 critical section을 실행하면 안된다.)
2. Progress
- critical section에 접근할 때, 하나의 스레드는 무조건 접근해야 한다.
(크리티컬 섹션에 들어가야하는데 아무도 안 쓰고 있으면 기다리지 않고 그냥 진입할 수 있어야 한다.)
3. Bounded Waiting
- 특정 스레드가 starvation이 발생해서는 안된다.
(critical section에 들어가는 걸 요청했는데 누가 사용하고 있으면 기다려야 할 것이다.
그러나 무한정 기다리고만 있게 하면 안된다.)
지금부터 동기화 문제를 해결하는 몇가지 SW 솔루션들을 이 조건들에 따라 알아볼 것이다.
- Interrupt-based Solution
- Peterson's Solution
◆ Interrupts-based Solution
critical section에 들어갈 때 interrupt를 disable하는 방식.
entry section에서 interrupt를 disable하는 것. (non-preemption으로 설정한다.)
그리고 citical section에 들어가면 스스로 나올 때까지 CPU를 혼자 독점할 수 있다.
exit section에서 다시 interrupt를 enable시킨다.

⚠️ 문제점:
critical section이 굉장히 길면?
→ 한 프로세스가 CPU를 독점하게되고, 따라서 어떤 프로세스는 Starvation이 일어날 수도 있다.
- bounded waiting 조건을 만족하지 못한다.
- 멀티 프로세싱인 경우, 한쪽 코어만 disable하는 게 아니라 모든 코어를 다 disable 하게 되어버리면 CPU가 낭비되는 문제가 발생할 수 있음
◆ Peterson 들어가기 전, 하나의 SW 솔루션 제시?
우선 생각해보자.
ex)
이런 방식으로 동작하는 거, 가능할까?
2개의 core에서 프로세스 i, 프로세스 j가 동작하려고 한다고 하자.
turn이라는 공유 변수를 두고, turn에 따라 각 critical section이 따로따로 실행되도록 하고싶다.
먼저 코드를 실행하는 쪽에서 turn을 자신의 프로세스(i 또는 j)로 설정할 것이다.


while (turn == j); 는 이 조건이 만족하는 한 대기한다는 뜻임. (무한루프)
처음에 turn == i라고 하자. 그러면 i 프로세스는 while (turn==j); 에 안 들어가고, 크리티컬 섹션을 실행할 것.
실행이 완료되면 turn = j로 바꾼 후 remainder section을 실행함.
그러면 j 프로세스는 그제서야 while(turn==i)문을 탈출하고 크리티컬 섹션을 진행할 것임.
그동안 i는 다시 entry section으로 가는데, turn == j 니까 기다림.
이렇게 쓰는거 가능할까?
→ ㄴㄴ 불가능.
mutual exclusion은 보존됨.
turn이 동시에 i이고 j일 수는 없기 때문.
근데 progress 는?
i가 먼저 critical section실행 끝내고, 이후 j도 끝냈다.
j가 다시 entry로 돌아와서 critical section 실행하고 싶은데, i는 여전히 remainder section을 실행중인 상황이라하자. (critical section 들어갈 필요가 없는 상황)
그러면 지금 critical section 쓰는 사람이 아무도 없는데도, j는 못 들어가고 기다리게 됨. (i가 다시한번 critical section을 실행한 후에 turn을 j로 바꿔줘야만 들어갈 수 있음 ㅠ)
- 즉, 무조건 번갈아서 실행되어야만 한다는 뜻.
그러면 Bounded Waiting은?
유한대기 인거같은데?
◆ Peterson's Solution
위 방법에서 flag[2]라는 변수를 추가해 발전시킨 방법이다.
아쉽게 2개의 core에서만 적용 가능한 방법이다. 하지만 방법론으로는 좋은 아이디어를 가지고 있다.
이 솔루션에는 두 변수가 등장한다.
- int turn : 누가 critical section에 들어갈 차례인지를 나타낸다.
- bool flag[2] : 해당 프로세스가 critical section에 들어갈 준비가 되었는지를 나타낸다.
ex)
프로세스 i의 코드가 다음과 같다고 하자.


프로세스 i의 입장에서 보자.
- entry section에서, 프로세스 i가 준비가 되었다는 플래그를 올림.
- 이후 turn을 j로 바꿔줌. ← 프로세스 j한테 순서를 먼저 양보하고자 하는 것.
그리고 while문을 통해 프로세스 j가 준비되었는지 확인을 하는거임.
- 만약 프로세스 j가 준비가 되어있고, j의 턴이라면, 기다림. (무한루프)
- 그렇지 않으면 (j가 준비되어 있지 않거나, j의 턴이 아니라면), 내가 크리티컬 섹션에 들감.
- j의 턴이 아닌 경우는: i가 플래그를 올리고, 턴을 j로 바꾼 후, j도 플래그를 올리고, 턴을 i로 바꾼 경우를 의미함.
- 즉 둘다 플래그를 올렸다면, 먼저 플래그를 올린 i가 크리티컬 섹션에 먼저 들어갈 수 있는 것!
- 나오자마자 exit section에서 자신의 플래그를 false로 바꿔줌.
만약 자신의 플래그를 바꿔주지 않고 끝내면, deadlock이 발생함.
피터슨 방법이 세 조건을 만족하는지 확인해보자.
● Mutual exclusion
flag, turn 변수를 통해 충족.
두 flag가 true이더라도, turn은 i또는 j 하나만 가능하기 때문에 동시에 critical section을 실행하는 일은 없음.
● progress
프로세스가 critical section을 나오자마자 flag 변수를 false로 설정함으로써
critical section 입장을 기다리던 프로세스가 바로 진입할 수 있도록 도와 주기 때문에 progress 또한 충족
아까와 같이, i가 먼저 critical section실행 끝내고, 이후 j도 끝냈다. j가 다시 entry로 돌아와서 critical section 실행하고 싶은데, i는 여전히 remainder section 실행중인 상황이라하자. 아까는 이런 경우 j가 바로 못 들어가고 계속 기다려야 했었다.
피터슨에서는 이를 해결한다.
- i가 먼저 실행 끝내면, turn = j, flag[i] = false.
- 이후 j가 끝내면, turn = i, flag[j] = false.
- i가 여전히 remainder 실행중이고, j는 entry로 돌아와서 flag[j] = true로 바꿨다고 하자.
- 그러면 이 시점에서 turn = i, flag[i] = false, flag[j] = true.
- 비록 turn은 i지만, 현재 프로세스 i가 당장 critical section을 실행할 필요는 없으니까, j가 안기다리고 바로 들어갈 수 있음!
- 이전에 turn만 쓰던 코드에서 발생했던 문제 해결.
● Bounded waiting
j 프로세스가 들어가고 싶을 때 turn은 i로 지정하고 i가 들어가고 싶을 때 그 반대로 지정하므로, 반드시 상대 프로세스가 먼저 진입하고 싶다면 할 수 있도록 한다.
때문에 모든 프로세스는 유한 대기한다. (만약 스스로 지정하게 한다면 무한 대기 가능성 있음)
▶ 그렇다면 turn을 상대로 지정하지 않고 자기자신으로 지정한다면?
다음 순서로 진행될 시 문제가 발생한다. (i의 코드, j의 코드)
- flag[i] = true
- flag[j] = true
- turn = i
- while(flag[j] && turn == j) ;
- flag[j] == true이지만, turn == i이므로, 프로세스 i가 진입
- turn = j
- while(flag[i] && turn == i) ;
- flag[i] == true이지만, turn == j이므로, 프로세스 j도 진입
=> 두 프로세스가 동시에 크리티컬 섹션에 진입!! ㅠㅠ
◆ Peterson's Solution - 한계
이상적으로 생각했을 때는 솔루션이 되는데, 실제 컴구에선 작동 안 함.
Operation들의 실행 순서가 하드웨어적 측면에서 서로 뒤바뀔 수 있다는 것. (reorder)
※ Reorder (또는 Out-of-order execution(OoOE))
CPU의 효율을 최대화하기 위해 명령어를 비순차적으로 처리하겠다는 의미다.
다음 코드를 보자.
두 코어1,2에서 flag과 x를 공유 변수로 사용하고 있다.
# share var boolean flag = false; int x = 0; # core 1 while(!flag); print(x); # core 2 x = 100; flag = true;
이론상, 코어2가 x=100을 지정한 후 flag를 true로 바꿀 때까지 코어1은 while문의 무한루프에 빠지게 된다.
비로소 flag=true가 되면, 코어1은 while문을 빠져나오고, 100으로 업데이트된 x를 출력한다.
그러나 이렇게 되지 않는다.
core1에서 core2를 기다리는 과정이 비효율적이기 때문이다. 이때 reorder가 동작한다.
다음과 같이 코어2의 instruction 순서를 바꿔버린다.
# core 2 flag = true; x = 100;
reorder의 조건은, instruction에 포함된 두 변수가 독립적인 경우이다. 코드에서 x와 flag는 서로 동작에 영향을 주지 않기 때문에 reorder할 수 있다.
위 코드처럼 reorder 되는 경우, 코어1에서 즉시 while문을 빠져나오며, 코어2에서 x=100으로 업데이트 하기 전에 코어1에서 print(x)를 하여 0을 출력할 수도 있다는 것이다.
따라서 피터슨 솔루션을 적용한다해도, 둘이 동시에 크리티컬에 들어갈 수 있는 경우가 생긴다는 것.
ex)
P0에서 flag [0] = true가 먼저 실행되는 것이 아니라, turn = 1이 먼저 실행되어 P1이 들어갈 수 있는 설정을 만들어 줄 수도 있다는 의미다.

순서가 바뀌어서 p0에서 turn=1로 바꾸는 걸 먼저 처리함. 그런데 아직 flag[0] = true로 하기 전에, p1이 turn=0으로 바꾸고, flag[1]을 true로 바꾸고, while문에 도달했다고 하자. 이 시점에서 turn=0이지만, 아직 flag[0] = false이므로 p1이 while에 안 들어가고 크리티컬 섹션에 들어갈 것.
그러나 바로 다음에 p0에서 아까 실행 했던 flag[0] = true 코드를 실행함. 그러면 flag[1] = true이지만 turn = 0이므로 p0 역시 크리티컬 섹션에 들어가게 된다.
따라서 결국은, SW에서 해결하기 어렵기 때문에 HW적 솔루션이 필요하다.
=> Memory Barrier로 해결 가능. (reorder 방지)
◆ Hardware Support for Synchronization
Uniprocessor인 경우에는, 단순히 인터럽트를 비활성화 하면 된다.
그러나 일반적으로 멀티프로세서인 경우 너무 비효율적임!!
다음 두 가지 형태의 하드웨어 솔루션을 알아볼 것이다.
- Memory barriers
- Atomic instructions
- Atomic variables
◆ Memory Model
메모리 모델에는 기능에 따라 두가지 종류가 있다.
- Strongly ordered – 메모리 값이 변경되는 즉시 모든 프로세서들에게 알려준다. (그만큼 성능 저하)
- Weakly ordered – 메모리 값이 변경되더라도 모든 프로세서들에게 즉시 알려주지는 않는다.
따라서 변경된 내용을 모르는 프로세서가 있을 수 있음. (대부분의 현대 메모리는 이런 방식 사용함.)
멀티스레드 환경, 멀티코어 환경에서 각 CPU는 메인 메모리에서 변수값을 참조하는 것이 아니라, 각 CPU의 캐시 영역에서 메모리를 참조하게 된다.
Weakly ordered의 경우에는, 이때 메인 메모리에 저장된 값과 CPU 캐시에 저장된 값이 다른 경우가 있다는 것이다.
여기서도 memory barrier을 사용할 수 있는데, memory barrier은 연산 순서 리오더링 방지 + 메모리의 변화가 다른 모든 프로세서에 전파(가시화)되도록 하는 명령어임.
◆ Memory Barrier
"명령어 순서 고정" + "메모리 변경 전파(가시성 보장)"
컴파일러나 CPU에게 barrier 명령문 전/후의 메모리 연산을 순서에 맞게 실행하도록 하는 기능이다.
이렇게 하여 reorder를 방지한다.
또한 메모리 변경 내용을 다른 CPU/프로세스가 메모리 변화를 볼 수 있도록 강제한다.
다음과 같이 메모리 배리어라는 instruction을 중간에 두면, 그 앞뒤로는 instruction의 순서가 바뀔 수 없게 된다.

◆ Atomic Instructions
중간에 끊어지지 않고 한번에 실행되는 instruction들
현대의 CPU에서는 특정한 메모리의 한 워드의 내용을 검사 및 변경하거나, 두 개의 워드의 내용을 atomic하게 교환할 수 있는 CPU 명령을 제공한다. (atomic: 이 명령의 실행이 중간에 끊어지지 않는다는 의미.)
대표적으로, 다음 두가지 CPU 명령이 존재한다.
☆ 이 함수들이 중간에 끊어지지 않고 한번에 이루어진다는 것이 중요.
1. Test-and-Set instruction
boolean test_and_set (boolean *target)
{
boolean rv = *target;
*target = true;
return rv:
}
: 메모리 값을 검사하고(true/false 등), 동시에 설정(set)까지 하는 원자적 연산
타겟의 원래 값을 읽어냄(반환)과 동시에, 타겟의 값을 true로 만드는 명령.
🔸 용도
- 주로 Spin Lock (회전 락) 구현에 사용됨
2. Compare-and-Swap instruction
int compare_and_swap(int *value, int expected, int new_value)
{
int temp = *value;
if (*value == expected)
*value = new_value;
return temp;
}: 지정된 메모리 위치의 값이 예상한 값이면 → 새 값으로 교체하는 원자적 연산
value의 원래 값을 읽어냄(반환)과 동시에, value가 expected와 같다면 value의 값을 new_value로 바꿔주는 명령.
- *value== expected일 때만 *value= new_value로 원자적으로 교체
- 실패하면 아무 일도 안 하고 false 반환
🔸 용도
- 락 없이(lock-free) 상태 변경할 때 사용
- 대표적인 예: Lock-Free Stack, Queue, Atomic Counter 등
■ Atomic Variable
일반적으로 atomic instruction들은 다른 동기화 도구의 구성 요소로 사용된다.
1) test_and_set 예제
do {
while(test_and_set(&lock));
/* critical section */
lock = false;
/* remainder section */
} while(true)- entry section 부분에서 test_and_set을 사용했다.
- lock의 초기값이 true인 경우, test_and_set을 하면 false값이 반환되기 때문에 대기.
- lock의 초기값이 false인 경우에, test_and_set을 하면 true값이 반환된 후, lock이 true로 바뀜.
그러면 대기가 끝나고 critical section에 진입함. - 이때 다른 프로세스가 critical section에 진입을 시도하더라도, lock이 true로 바뀐 상태이므로 진입하지 못하고 while(test_and_set(&lock))에서 무한루프 돌게됨.
- 그렇게 혼자서 critical section 잘 실행한 후에, 끝나면 lock 값을 false로 바꾸면 됨.
2) compare_and_swap 예제
void increment (atomic_int *v)
{
int temp;
do {
temp = *v;
}
while (temp != (compare_and_swap(v,temp,temp+1));
}
주로 위와같은 반복문에서 많이 씀.
- v를 temp에서 temp+1로 바꾸려는 상황. (v값이 temp라고 예상중)
- 실제로 현재 v가 temp라면 temp+1로 바꾸고, 그렇지 않으면(중간에 다른 누군가가 v값을 먼저 바꾼 경우) 아무 일도 발생X
즉, 내 데이터가 최신 데이터인 경우에만 새로운 값으로 교체하는 instruction을 수행한다.
◆ 그러나, SW 입장에선 너무 복잡한 ㅠㅠ
ㄹㅇ 내 입장에서 너무 복잡함.
이전 솔루션은 복잡하고 일반적으로 애플리케이션 프로그래머가 접근하기 어렵다.
→ 그래서 Higher level에서 이것보다는 간단하게 데이터 동기화를 할 수 있는 방법을 제공해준다.
다음과 같은 도구들이 존재한다.
- Mutex Lock
- Semaphore
- Monitor (with Condition Variables)
◆ Mutex Lock
Mutual exclusive Lock.
acquire() 함수를 이용해 lock을 하고, release() 함수를 이용해 lock을 푼다.
acquire()과 release()는 HW 가 서포트해주는 atomic instructions를 사용해 구현되었으므로 믿을만하다.

available 하기 전까지는 계속 체크하면서 기다리다가, available한 경우 내가 available = false로 만들고, 실행.
실제 사용할 때는 다음과 같이 사용한다.

위 프로세스는 busy waiting을 해서, CPU를 계속 사용하면서 대기한다. (spin lock)
반면 리눅스에선 ready queue에 들어갔다가 나오는 방식이라, CPU를 양보할 수 있다.
그러나 상황에 따라 busy watiting을 하는 것이 오히려 더 나은 경우도 있으니 디자인 옵션으로 지정할 수 있다.
※ Mutex lock에는 두가지 방법이 있다.
1) busy wait 하는 Mutex
- acquire()을 계속 시도하고 있는 것. ( == spin lock)
2) block하는 Mutex
- ready queue에서 쉬면서 나올 때까지 기다리는 것.
※ Spin lock은 Mutex lock에 포함되는 개념이다. Mutex Lock의 일종임 ㅇㅇ
Spin lock의 장점
1) 구현하기 간단하다.
2) context switch 필요 없다. (block하는 경우, 잠겨있으면 다음 프로세스로 넘어간다. 코어 사용을 양보함)
→ acquire - release 사이가 짧은 경우 유리하다.
Spin lock의 단점
1) 시스템 resource를 많이 잡아먹는다.
2) lock holder 스레드(락을 하고있는 스레드)가 선점될 경우, starvation이 발생할 수 있다.
◆ Semaphore
CS에 들어가기 전에 "wait()"를 선언하고 CS에 들어갈 수 있고, 다 사용하고 난 후에는 "signal()"을 선언하여 release 한다.
wait()에서는 세마포어 값을 1 줄이고, signal()에서는 세마포어 값을 1 늘린다.
Semaphore는 lock보다 높은 레벨의 동기화를 구현해준다.
S라는 하나의 int형 변수를 두고, S가 state를 나타내도록 하는 방식이다.
→ 최대 S개의 task가 semaphore를 동시에 잡을 수 있다.
즉, lock과 비슷한데, 한개 이상의 entity가 동시에 잡을 수 있다는 차이가 있다.
Semaphore의 종류는 두 가지가 있다
- Counting semaphore
- S는 N(사용 가능한 리소스의 수)으로 초기화 되어있다.
- 주로 resource counting 에 사용한다. - Binary Semaphore ( Mutex Lock과 유사 )
- S는 1로 초기화 되어있다. S의 값은 항상 0 또는 1이다.
- 주로 mutual exclusion 보장에 사용한다.
Semaphore를 구현할 때 사용하는 operation들은 다음과 같다.

- wait()
: S가 0보다 커질 까지 기다리고(busy waiting) , S>0이면 S를 1 내린다. - signal()
: S를 1 올리고 나간다.
ex)
mutex라는 세마포어를 만들고 1로 초기화했다고 하자.
wait(mutex);
/* critical section */
signal(mutex);wait()에서 mutex의 값이 0이 된다. 그러면 나는 critical section에 들어간다.
이때 다른 프로세스가 해당 코드를 실행한다면, mutex의 값이 -1이 되어서 critical section에 들어올 수 없게 된다.
내가 critical section을 끝내고 나가면서 signal()을 해주면, 다시 mutex의 값이 ++되어서 기다리고있던 다른 프로세스가 접근 가능하게 된다.
ex)
P1에서 실행하는 S1작업과, P2에서 실행하는 S2작업이 있다고 하자.
무조건 S1작업이 S2작업보다 일찍 이루어지게 하고싶다면, 다음과 같이 작성하면 된다.
synch라는 세마포어를 만들고 0으로 초기화했다고 하자.
# P1
/* S1작업 */
signal(synch);# P2
wait(synch);
/* S2작업 */만약 P2가 먼저 wait에 도달하면, synch는 -1이 되어 기다리게 된다.
그러다가 P1이 S1 작업을 끝내고, signal에 도달하여 synch값을 올리면, 그제서야 P2는 기다림을 끝내고 S2작업을 수행할 수 있다.
◆ Semaphore without Busy Waiting (Block-WakeUp)
세마포어에다 waiting queue를 이용하는 방식.
waiting queue에 프로세스를 넣으면 해당 프로세스는 waiting state로 가며,
스케쥴러는 다른 프로세스를 선택해 실행할 수 있다.
즉 CPU를 다른 프로세스들에게 양보해줄 수 있기 때문에 상황에 따라 효율적일 수 있다.
앞서 봤던 wait 함수는 Busy Waiting 하는 방식이었다.
이는 기다리면서도 CPU 코어를 사용하는 방식이다. (계속 이제 들어가도 돼? 안돼? 물어봄)
세마포어를 busy waiting 없이 구현하는 방법도 있다. waiting queue를 이용하는 것이다.
세마포어는 waiting queue를 가지는 방식으로 구현되어 있다.
세마포어의 구조는 다음과 같다.

- value가 음수인 경우, value의 절대값은 세마포어를 대기하는 프로세스의 수를 의미한다. (기존과 다르게, 음수가 될 수 있다!!)
양수인 경우 남아있는 기존 세마포어처럼 남는 자원의 개수를 의미한다. - list는 세마포어를 대기하는 프로세스들의 리스트(linked-list)이다.
- 만약 value < 0이라 세마포어를 대기해야 하는 경우, 세마포어의 linked list에 연결한 후, block한다.
- 그러다가 자원이 반납 되면 깨워져서 자원을 사용할 수 있다.

이와 관련된 다음 두 operation이 존재한다.
- block – waiting queue로 옮기기. (busy waiting과 달리, CPU 코어를 사용하지 않는다.)
- wake up – waiting queue에서부터 ready queue로 옮기기. (waiting state → ready state)
다음은 block과 wake up을 사용해 no busy waiting으로 구현한 wait, signal 함수이다.

wait : S를 1 내린다.
프로세스가 세마포어를 기다려야 한다면, 이 프로세스는 세마포어에 대한 waiting queue에 추가된다.
그리고 해당 프로세스는 waiting state로 간다.
signal : S를 1 올린다.
(세마포어를 기다리는) block된 프로세스 리스트로부터, 하나를 꺼내서 깨운다. (ready queue로 옮김)
자원을 내놓았는데도 자원이 0이하라면, 아직도 기다리고있는 프로세스가 있다는 뜻이므로 다음으로 잠들어있는 프로세스를 깨운다. (기다리는 프로세스가 아무도 없다면, 내가 반납하면 남은 자원이 1 이상이어야 할 것임)
※ 이렇게 구현한 wait 및 signal 역시 critical section이라는 점에 유의.
※ Busy Waiting vs Block-WakeUp
일반적으로, CPU 소모를 줄일 수 있는 Block-WakeUp 방식이 좋음
그러나 Block-WakeUp 방식은 결국 오버헤드가 존재함
→ 어떤 프로세스를 waiting queue로 배치하거나, block된 프로세스를 ready queue로 배치할 때 오버헤드 발생
따라서 결론!
- critical section 길이가 길면, Block-WakeUp이 적당
- critical section 길이가 매우 짧으면, busy wait 가 적당
◆ Monitor
공유 데이터에 접근하려면 monitor 내부의 함수를 통해서만 접근할 수 있도록 하는 방법.
이때 모니터를 사용할 수 있는 프로세스를 제한하며, 나머지는 대기열에서 기다리도록 한다.
프로그래머가 따로 lock을 걸 필요가 없다.
동시 수행 중인 프로세스 사이에서 abstract data type의 안전 공유를 보장하기 위한 high-level 동기화 구조.
monitor 내부의 함수를 통해서만 공유 데이터에 접근할 수 있도록 한다.
(코딩하기 힘든 semaphore에 비해 프로그래머의 부담을 줄여주고, monitor가 알아서 해줌.)


- 모니터는 한번에 한 프로세스만 활용할 수 있다. (한 번에 한 프로세스만 모니터 내에서 active될 수 있다.)
- 프로그래머가 따로 lock을 걸 필요가 없다.
Programmers do not need to code the synchronization constraint explicitly!!만약 실행 도중 interrupt가 발생해 CPU를 빼앗기더라도, 어차피 모니터를 사용중인 건 나 하나니까 다른 애들이 공유 데이터에 접근할 일이 없다. (다른 애들은 밖에서 대기 중임)
active한 프로세스가 0이 될 때 기다리던 프로세스가 들어온다.
◆ Monitor with Condition Variable
Condition Variable이란 특정 조건을 만족하기를 기다리는 변수이며, 스레드 간 신호 전달을 위해 사용된다.
- 프로세스가 monitor 안에서 기다릴 수 있도록 하기 위해 Condition Variable사용
(자원이 있는지 여부/ 어떤 조건을 충족시키지 못해 잠들거나 깨울 때) - condition x, y : 자원이 있으면 바로 접근, 없으면 기다리게 함
(condition variable은 값을 가지는 변수가 아님! 신호 전달을 위해 사용)

condition variable은 wait 와 signal 연산에 접근 가능.
x.wait()
- 자원 x를 원하는 줄에 기다림
- x. wait()을 invoke한 프로세스는 다른 프로세스가 x.signal()을 invoke하기 전까지 suspend(유예)된다.
x.signal()
- 자원 x를 기다리는 다음 프로세스가 빠져나오도록 함.
- x.signal()은 정확하게 하나의 suspend된 프로세스를 resume(재개) 한다.
suspend된 프로세스가 없으면 아무 일도 일어나지 않음.
주의할 점은, wait와 signal의 구현이 세마포어 처럼 카운팅을 하는 방식이 아니기 때문에 wait와 signal의 순서가 중요하다는 것이다. 이런 이유로 추가적인 상황 변수를 사용하곤 한다.
ex)
S1이 S2 이전에 일어나야 한다고 하자.
모니터에는 각각 P1, P2가 invoke하는 프로시저 F1, F2가 존재한다.
condition variable x는 0으로 초기화된다.
다음과 같이 구현할 수 있다.

S1코드가 실행된 후 done을 true로 바꾸고, signal을 보내준다. 그러면 wait하던 F2에서 듣고 깨어나서 S2코드를 실행한다.
그냥 wait 하면 차피 signal 올 때까지 기다리지 않나? done은 왜썼지?
라는 의문이 들 수 있다. 이는 race condition 때문이다.
생각해보자. 만약 위 예시에서 done 변수가 없는 경우에, 일어날 수 있는 상황은 두 가지이다.
1) P2가 먼저 wait()를 하고 있는 상황에서, P1이 실행을 끝내고 signal()을 호출하는 경우
- 이 경우 P1의 실행이 끝난 후 순조롭게 P2를 깨울 수 있다.
2) P1이 빨리 실행을 끝내서 signal()을 호출한 후에, 뒤늦게 P2가 wait()를 호출하는 경우
- 이 경우 P1은 signal을 통해 잠든 프로세스를 깨우려고 할 테지만, 아직 잠든 프로세스가 없어서 아무 것도 하지 않고 넘어갈 것이다. 그러면 뒤늦게 잠든 P2를 깨워줄 프로세스가 아무도 없다.ㅠㅠ
이런 이유 때문에 done 변수를 사용한다. 이때 done 변수를 상황 변수(State Variable)라고 부른다.
'CS > 운영체제' 카테고리의 다른 글
| 8. Deadlocks (0) | 2023.10.16 |
|---|---|
| 7. Synchronization Examples (0) | 2023.10.16 |
| 5. CPU Scheduling (0) | 2023.09.20 |
| 4. Therad & Concurrency (0) | 2023.09.18 |
| 3. Processes (0) | 2023.09.13 |



