
센로그
10. Virtual Memory 본문
◆ 요점 정리
1. Virtual Memory
- logical memory - physical memory가 1:1로 매핑될 필요 없음
- backing store에 들어가있을 수도 있음.
- CPU 효용과 처리율 높이면서도, 응답 시간이나 turnaround(처리) 시간이 늘어나진 않는 조은 방법.
2. Virtual Memory 구현
- Demand Paging
- valid-invalid bit로 메모리에 존재하는지 아닌지 구분
- invalid인 경우 트랩 보내면, OS가 어떤 경우인지 판단
- invalid reference: 프로세스 중지
- page fault: 빈 프레임 찾아서 디스크로부터 읽어오고, valid로 수정
- 성능 EAT = (1-p)메모리 접근 시간 + p(페이지폴트 오버헤드 + 페이지 인 시간 + 페이지 아웃 시간)
- 여기서 p는 page fault rate
3. CoW
- 프로세스 생성 시에는 페이지 공유해서 쓰다가, 누군가 수정할 시에만 페이지 복사해주는 방식.
4. Page Replacement 알고리즘
- FIFO
- Optimal
- LRU
- LRU 근사
- Reference bit 사용
- Second-Chance 알고리즘
- Reference bit 사용
5. Thrashing
- Page fault가 많이 나서 디스크로부터 읽어오느라 I/O burst 늘고 CPU busrt 급감.
- 근데 CPU burst가 줄어드니까.. OS 입장에선 얘 할일 없나보네? 하고 일 더 줘서 더 큰일나는 경우
6. 커널 메모리 할당
- Buddy System Allocator: 2의 제곱 단위로 메모리 할당 및 관리
- Slab Allocator: 사용할 Object 사이즈별로 미리 캐싱
◆ Virtual Memory
코드는 실행되려면 메모리에 올라와 있어야 한다. 그러나 전체 코드가 동시에 사용되는 경우는 거의 없다.
따라서 아이디어는, "프로세스 전부를 다 메모리에 올리지 않고도 실행할 수 있다!" 라는 것.
→ 실행을 위해 필요한 부분만 메모리에 올리는 방식
→ Logical address space가 Physical address space 크기보다 훨씬 커도 실행할 수 있음!
→ 프로그램이 더 이상 physical memory의 한계에 제약받지 않아도 됨.
프로그램을 일부만 메모리에 올려도 되면 어떤 점이 좋을까?
- 프로그램이 더 이상 실제 물리 메모리에 의해 제약을 받지 않아도 됨.
사실상 매우 거대한 가상 주소 공간에 넣을 프로그램도 작성할 수 있게 되어 프로그래밍이 간단해짐. - 물리 메모리를 실제로 덜 먹을테니까 동시에 프로그램을 더 많이 실행할 수 있음
→ CPU 효용과 처리율도 높아지면서도, 응답 시간이나 턴어라운드 시간이 늘어나지도 않음. - 프로세스 생성 시에도 더 효율적임.
- 프로그램의 일부를 메모리에 적재하거나 스왑하는데 필요한 입출력이 적어지므로 프로그램이 더 빠르게 돌 것임.

가상 메모리 virtual memory는 logical 메모리를 실제 physical 메모리와 구분하는 것으로 시작함.
이러면 실제 physical 메모리가 얼마 없어도 CPU는 매우 거대한 logical 메모리를 보고 있는 것처럼 해줄 수 있음.
이러면 logical 메모리 덕분에 프로그래머가 남은 physical 메모리량 걱정 안해도 돼서, 프로그래밍 자체에만 집중할 수 있게 해줘서 좋음.
◆ Virtual Address Space
프로세스가 메모리에 저장되는 logical 관점의 뷰를 의미함.
보통 프로세스가 어떤 logical 주소(0이라든가)에서 시작하고, 연속 메모리에 존재하게 될 것임.
MMU는 이 logical address들을 physical address로 매핑해줌.
Virtual memory는 다음 방식들을 통해 구현될 수 있다.
- Demand paging
- Demand segmentation
◆ Demand Paging
페이지가 필요할 때만 올리는 것.
작동 방식을 보자.
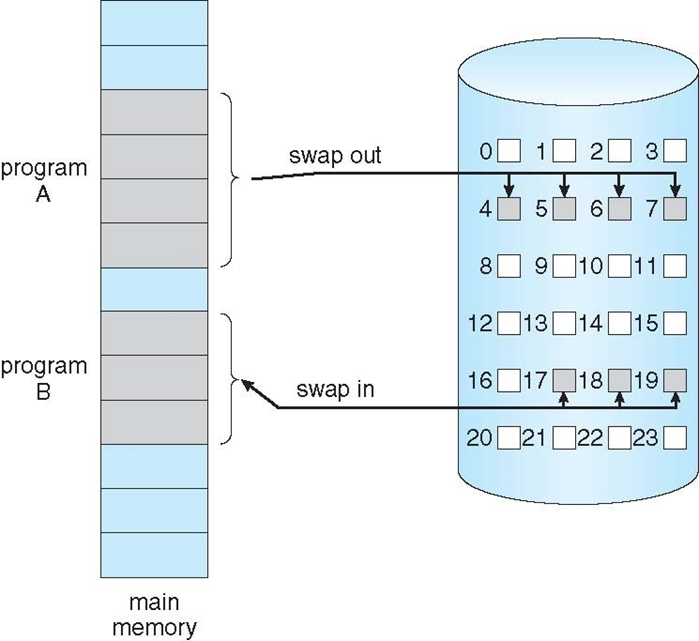
어떤 페이지가 필요하다? 그러면 우선 메모리에서 참조할 수 있는지(올라와 있는지) 확인함.
- 만약 invalid한 참조라면 abort
- 메모리에 없다면, 메모리로 꺼내서 갖고옴
이러한 방식은 swapping을 활용한 페이징 시스템과도 유사함.
- Lazy swapper: 필요하지 않은 페이지는 메모리로 swap in 하지 않음.
- 페이지를 처리하는 swapper을 pager 라고 부름.
각 페이지 테이블 엔트리는 valid-invalid bit를 갖고 있음. 지난번에 9장에서 언급했던 걔 맞음.
주소가 합법인지 아닌지 나타내던 애들. 근데 나타내는 정보가 조금 추가됨.
메모리에 올리려는 것이 현재 메모리에 존재하는지 아니면 디스크에 존재하는지 알아야 함.
- v: 주소가 합법이면서, 메모리 위에 있다
- i: 주소가 유효하지 않거나, 메모리 위에 있지 않다(디스크에 있다)

address translation 도중에, 만약 valid-invalid bit가 i라면? → page fault.
page fault는 보호 문제에 걸리는 게 아니라, 메모리에 없는 페이지에 접근하려고 하는 경우를 의미함. 이 경우 트랩이 발생함.

그림을 보면 valid-invalid비트가 i인 페이지를 프로세스가 접근하지 않은 경우, 아예 메모리에 올라오지 않는 것을 알 수 있음.
◆ Handling Page Fault
프로세스가 메모리에 없는 페이지에 접근하려고 하면 page fault가 발생하게 됨.
- 이렇게 Page fault가 일어난다면 CPU는 운영체제에게 알리고, 운영체제는 잠시 동안 CPU 작업을 멈춤
- 그리고 Disk에서 해당 부분을 찾아 실제 메모리의 비어있는 Frame에 올리고, Page Table의 해당 부분의 Bit를 Valid로 갱신함.
- 그 후 Page fault를 일으켰던 명령어를 다시 실행하여 작업을 재개함
Page fault를 처리하는 구체적인 방법을 알아보자.
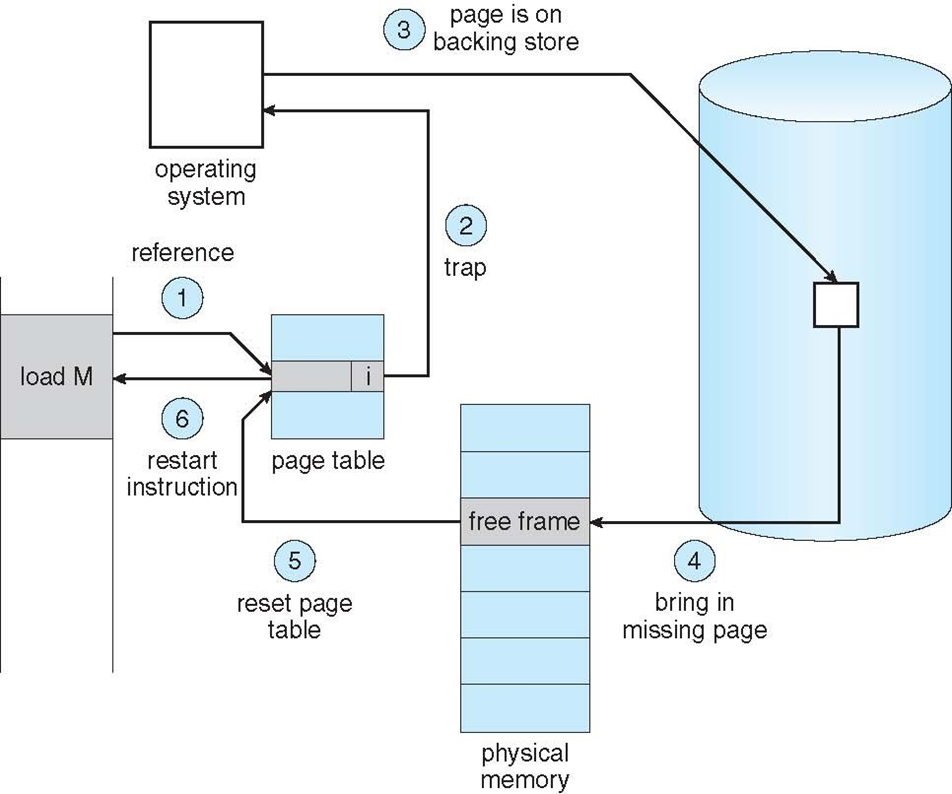
메모리를 참조하려면 우선 MMU의 TLB부터 확인함. 여기에 페이지에 대한 정보가 있으면 바로 해당 프레임으로 접근함.
그러나 처음 참조하는 페이지의 경우, TLB Miss가 나서 페이지 테이블을 들여다 볼 것임.
- 페이지 테이블을 통해 페이지를 참조(reference)하려고 하는 해당 페이지가 invalid(0) 하다면 MMU가 OS에 트랩을 발생시킨다.
- OS는 다음 중 어느 경우인지 확인한다.
- invalid reference: 부적절한 참조(invalid reference)라면 프로세스를 중지(abort)한다. (부적절한 참조 == 참조할 수 없는 곳을 참조)
- page fault: 그저 메모리에 없는 것(just not in memory)이라면 이제 메모리에 올리면 됨. 3번과정으로 넘어간다. - 페이지를 올릴 수 있는 비어있는 프레임(Free Frame)을 찾는다.
- (디스크에 있던) 페이지를 메모리의 해당 프레임에 읽어온다.
- 페이지 테이블의 valid-invalid bit를 valid로 수정한다.
- page fault를 유발했던 프로세스를 다시 실행한다. 그러면 마치 페이지가 처음부터 메모리에 존재했던 것 마냥 돌아갈 것임.
◆ Demand Paging 성능
EAT = (1-p)*메모리 접근시간 + p(page fault 오버헤드 + page out 시간 + page in 시간)
Demand Paging의 성능을 계산하는 방법에 대해 알아보자.
Page Fault가 발생할 확률을 p라 하자. (0 ≤ p ≤ 1)
- p = 0이면 page fault 발생 안 하는 것.
- p = 1이면 항상 page fault가 발생하는 것.
Demand Paging된 메모리의 Effective Access Time(EAT)를 계산해보자.
EAT는 다음과 같이 계산한다.

- EAT = (1-p)*메모리 접근시간 + p(page fault 오버헤드 + page out 시간 + page in 시간)
- EAT는 p의 값에 비례한다.
- 만약 page fault가 일어나지 않는다면, EAT는 메모리 접근 시간과 동일하다.
- 그러나 page fault가 일어난다면, 이 페이지를 디스크에서 읽어서 프레임에 올리고, 만약 프레임 자리가 없다면 내리고.. 많은 오버헤드가 발생한다.
◆ Copy-on-Write (COW)
부모-자식 프로세스 관계에서, 누군가가 공유 페이지를 수정하는 경우에만 페이지를 복사하는 것
fork() 시스템 호출을 생각해보자. 원래 fork()는 부모의 페이지를 복사해서 자식에게 주었음.
그러나 대부분의 자식 프로세스가 생성 즉시 exec() 시스템 호출을 하기 때문에 부모의 주소 공간을 복사하는게 딱히 필요 없을 수도 있음.
대신 부모와 자식 프로세스가 초기에는 같은 페이지를 공유하는 Copy-on-Write(COW) 기법을 사용하면 됨. 이런 공유 페이지는 COW 페이지로 표기를 해둠. 즉, 父子 중 하나가 공유 페이지에 쓰기를 시작하면 공유 페이지의 복사본이 생성된다는 뜻임.
그림을 보자.
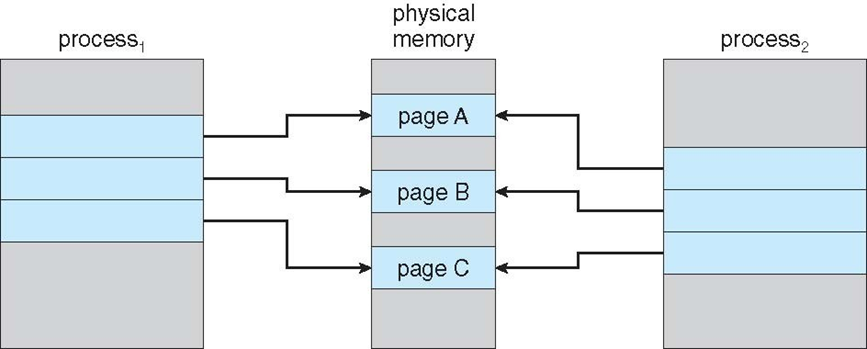
공유 페이지를 읽기만 하는 과정. 페이지가 복사되지 않았음.

프로세스1이 페이지 C를 수정하려고 하자, C의 복사본이 생성되어 여기서 수정하도록 함.
◆ Free-Frame List
사용 가능한 프레임 목록
- page fault가 발생하면 OS는 해당 페이지를 디스크에서 꺼내와서 프레임에 올려줘야 함. 이때 Free-Frame을 찾아서 거기다가 읽어줘야 할 것임.
- 대부분의 운영체제에서는 사용 가능한 프레임 목록(Free-Frame List)을 갖고 있음. 이 목록은 위의 문제에 대한 요구사항을 만족하는 사용 가능한 프레임들이 있는 창고임
- 관리 방법은 구현에 따라 다름

- 운영체제에서는 zero-fill-on-demand 기법으로 사용 가능한 프레임을 할당해 줌. 프레임들은 할당되기 전에 "0으로 초기화"되어 기존 내용물이 다 지워짐.
- 시스템이 시작하면 모든 사용 가능한 메모리를 사용 가능한 프레임 목록에 넣어줌.
- 사용 가능한 프레임에 대한 요청을 받을 때마다 여기서 하나씩 꺼내줌.
◆ Page Replacement
만약 Page Fault 나서, 디스크에서 찾아와서 프레임에 올리려는데 Free-Frame이 없으면 어떡함?
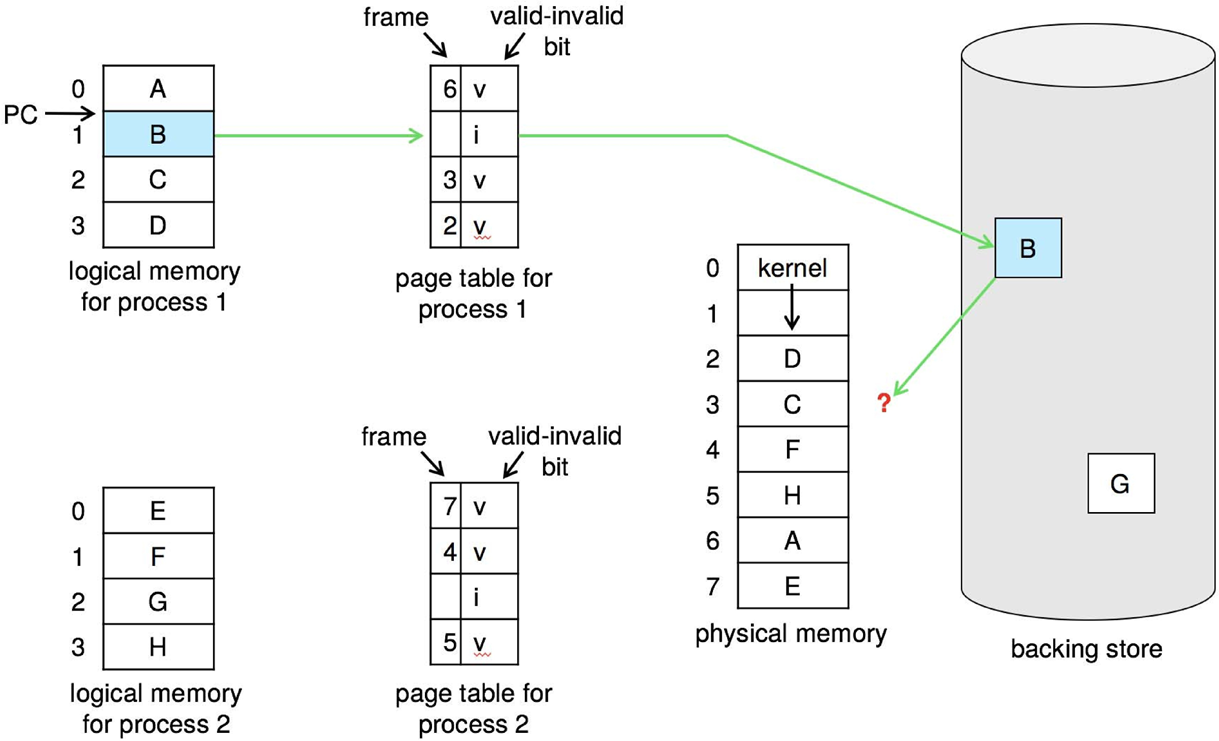
B 페이지 폴트 나서, 디스크에서 찾았는데. 어? 빈 프레임이 없네? 어떡하지?
→ Page Replacement 진행해야 함. 말 그대로 프레임을 할당받은 페이지를 교체하는 것.
그러기 위해서는 현재 자신이 차지하고 있는 Frame을 지금 당장 실행해야 할 Page에게 넘겨줄 Victim Frame을 찾아야 함.
프레임을 넘겨줄 때도 다양한 방법이 존재함. 아예 종료하거나, swap out하거나, ...
우리의 목표는 어떤 걸 내리고 올릴건지를 잘 결정해서, page fault rate를 낮추는 것이다!!
※ 참고 Page Replacement 알고리즘이 Victim Frame을 찾는 것을 도와줄 수 있는 요소로 바로 Modify Bit가 있다. Modify Bit는 현재 메모리에 올라가 있는 Page들 중에서 내부 데이터가 바뀌었는지를 알려주는 Bit를 의미한다.
|
※ 내부 데이터가 바뀌었다면 Disk와의 동기화를 위해 Swap-out 되어야 함.
이러한 Swap-In / Swap-out은 많은 비용을 발생시킨다.
따라서 Victim Frame을 찾을 때는 Modify Bit가 0인, 즉 Swap-out 될 필요 없는 Frame을 우선적으로 찾음.
Swap-out 될 필요가 없으니 그 자리에 덮어 씌어버리면 되기 때문!
◆ Basic Page Replacement
기본적인 페이지 교체 과정을 보자.

1. 원하는 Page를 Disk에서 찾는다.
2. 비어있는 Frame을 찾는다.
a ) 비어있는 Frame을 찾았다면 사용하면 된다!
b ) 비어 있는 Frame이 존재하지 않는다면 Page Replacement 알고리즘을 통해 Victim Frame을 찾는다.
c ) 필요 시, Victim Frame을 디스크에 적어준다.
3. Disk에서 가져온 Page를 2번 과정에서 찾은 Frame에 넣는다.
4. Page Table을 갱신하고 프로세스 실행을 재개한다.
그러면 구체적으로는 어떤 방식으로 Victim Frame을 찾을까?
지금부터 Page Replacement 알고리즘들을 살펴볼 것임.
◆ Page Replacement Algorithms
- Frame-allocation algorithm
- 각 프로세스마다 프레임을 얼마나 할당할지에 관한 방법 - Page-replacement algorithm
- 페이지 교체를 해야할 때 교체할 프레임은 어떻게 선택할지에 관한 방법
- 이 알고리즘에 따라 page fault rate가 결정된다.
알고리즘을 평가할 땐 특정 연속된 메모리 참조에서 돌려보고, page fault가 얼마나 발생했는지를 측정함. 여기서 이 연속된 메모리 참조를 참조 연속 reference string이라 부름. 이건 인공적으로 만들어주거나(랜덤수 생성기 등으로) 주어진 시스템을 추적해서 각 메모리 참조의 주소를 기록하는 식으로도 만들 수 있음.
후자의 경우 상당히 큰 수의 자료를 생성하게 됨. 자료량을 줄이려면 두 가지 사실을 사용하면 됨.
- 첫번째로 주어진 페이지 크기(페이지 크기는 주로 하드웨어나 시스템에 의해 고정된 크기임)에서 전체 주소보다는 페이지 수만 고려하면 됨.
- 두번째로는 참조 페이지 p가 있을 때 바로 페이지 p에 대한 모든 참조를 하면 절대로 page fault 가 일어나지 않는다는 것임. 페이지 p는 처음 참조할 때 메모리에 있을테니, 바로 즉시 다음에 참조를 할 경우 부재가 발생하지 않음.
이제 Page Replacement 알고리즘을 종류별로 보러 가자.
◆ FIFO Page Replacement
먼저 올라간 페이지부터 교체하는 것.
메모리 안에 있는 페이지를 담는 FIFO 큐를 사용하면 쉽게 구현할 수 있음.
ex)
다음 예시를 보자.
- Reference string: 7,0,1,2,0,3,0,4,2,3,0,3,0,3,2,1,2,0,1,7,0,1
- 프레임 수: 3개 (한 프로세스가 동시에 프레임에 올릴 수 있는 페이지 수가 3개/0

- 처음 3번 까지는 빈 프레임이 있으니 무난하게 잘 올라감.
- 2번 페이지 올리려는데, 빈 프레임이 없네?
→ 가장 처음으로 올라갔던 페이지 7번을 2번으로 교체함. - 0번은 올라와있으니까 패스
- 3번 페이지 올리려는데, 빈 프레임이 없네?
→ 올라간지 가장 오래 된 페이지인 0번을 3번으로 교체함. - 다음 참조는 0이라 또 page fault 발생
→ 1번을 0번으로 교체함.
이런 식으로 진행된다.
page fault는 총 15번 발생한 것을 확인할 수 있다.
■ FIFO Page Replacement - Performance
FIFO 페이지 교체 알고리즘은 이해하기도 쉽고 구현하기도 쉬움. 근데 성능이 언제나 좋진 않음.
교체 당한 페이지가 한참 전에 초기화할 때 사용했던 모듈이라 더 이상 필요하지 않을 수도 있지만,
반대로 자주 사용하기 때문에 처음부터 초기화를 해줬던 메모리를 담고 있는 페이지일 수도 있음.
우리가 현재 사용 중인 페이지를 교체해준다 하더라도 제대로 돌긴 함. 현재 사용 중인 페이지를 교체해줘도 바로 다음 번에 또 부재가 발생해서 해당 페이지를 다시 갖고 오겠지. 물론 다른 페이지를 또 교체해주겠지만. 그러므로 잘못 교체했다가는 페이지 부재율이 높아져 프로세스 실행 시간이 느려짐. 그런다고 해서 잘못된 실행을 야기하지는 않음.
FIFO 페이지 교체의 문제점을 보려면 다음 참조 연속을 예시로 들면 됨:
1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5
위의 참조 연속을 여러 프레임 수에 대해 적용했을 때의 페이지 부재 수를 정리한 그래프임:
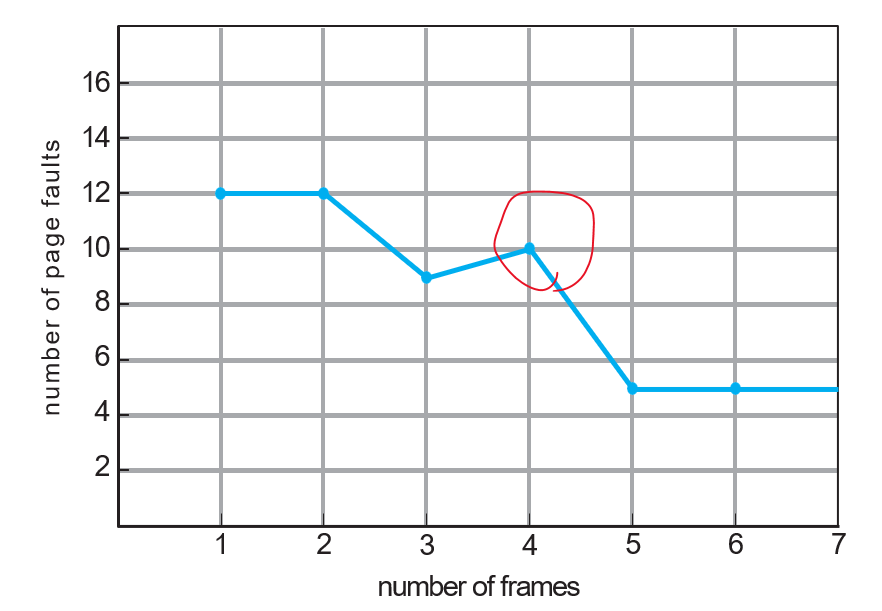
그래프를 보면, 프레임 네 개짜리에서 발생하는 부재 수(10 번)가 프레임 세 개짜리에서 발생하는 부재 수(9 번)보다 더 큼.
이런 예측 불가한 결과를 Belady's anomaly(벨라디의 변이)이라 부름. 어떤 페이지 교체 알고리즘이 주어졌을 때, 할당 가능한 프레임 수가 증가할 때 페이지 부재율이 오히려 증가할 수 있다는 것임. 누구나 메모리를 증가시키면 성능이 좋아질 거라고 하지만, 초기 연구에 의하면 이게 언제나 참은 아니라는 것을 알 수 있음.
즉, 무작정 할당 가능한 프레임 수를 증가시키는 게 해답이 될 수는 없다!
◆ Optimal Page Replacement
가장 오랜 기간 동안 사용하지 않을 페이지를 교체하는 것.
벨라디의 변이 덕분에 optimal page-replacement 알고리즘을 개발하게 됨.
모든 알고리즘 중에서 page fault rate가 가장 낮고, 벨라디의 변이가 발생하지 않는다.
→ 이런 알고리즘을 최적 알고리즘이라고 함. 더 나은 건 없다는 뜻
ex)
이 방법을 사용한 예시를 보자.
아까와 동일한 문제를 최적 페이지 교체로 풀어보자.
- Reference string: 7,0,1,2,0,3,0,4,2,3,0,3,0,3,2,1,2,0,1,7,0,1
- 프레임 수: 3개 (한 프로세스가 동시에 프레임에 올릴 수 있는 페이지 수가 3개)

- 2번 페이지가 올라가는 시점에서, (7,0,1) 중 가장 오랫동안 사용하지 않을 페이지는 7번
- 3번 페이지가 올라가는 시점에서, (2,0,1) 중 가장 오랫동안 사용하지 않을 페이지는 1번
- 4번 페이지가 올라가는 시점에서, (2,0,3) 중 가장 오랫동안 사용하지 않을 페이지는 0번
이런 식으로 진행하는 방식이다.
page fault는 총 9번 발생한 것을 확인할 수 있다. 위 문제에서 최초 3번은 공통이니, FIFO보다 훨씬 좋음!
근데 최적 페이지 교체 알고리즘은 구현하기가 어려움. 앞으로 참조 순서가 어떻게 될지를 미리 알아야하니까.
결과적으로 최적 알고리즘은 오로지 다른 알고리즘과 비교할 때만 사용함.
예를 들어 어떤 새로운 알고리즘이 최적은 아니더라도 최악의 경우 최적 알고리즘의 12.3%의 성능을 내고, 평균적으로는 4.7%다~ 등을 판단할 때 사용함.
◆ LRU Page Replacement
가장 오랜 기간 동안 사용하지 않은 페이지를 교체하는 것.
최적 알고리즘이 현실적으로 불가능하다면 최대한 최적에 근사하는게 좋을 것임.
만약 가장 최근 과거로 미래를 근사할 수 있다면, 가장 오랜 기간동안 사용하지 않은 페이지를 교체해줄 수 있음. 이게 바로 least recently used (LRU) 알고리즘임.
LRU 알고리즘에서 사용하는 시간은 각 페이지가 최근에 언제 사용됐느냐임. 페이지를 교체할 때 LRU는 가장 오랜 기간 동안 사용하지 않은 페이지를 선택함.
ex)
이 방법을 사용한 예시를 보자.
아까와 동일한 문제를 LRU로 풀어보자.
- Reference string: 7,0,1,2,0,3,0,4,2,3,0,3,0,3,2,1,2,0,1,7,0,1
- 프레임 수: 3개 (한 프로세스가 동시에 프레임에 올릴 수 있는 페이지 수가 3개)
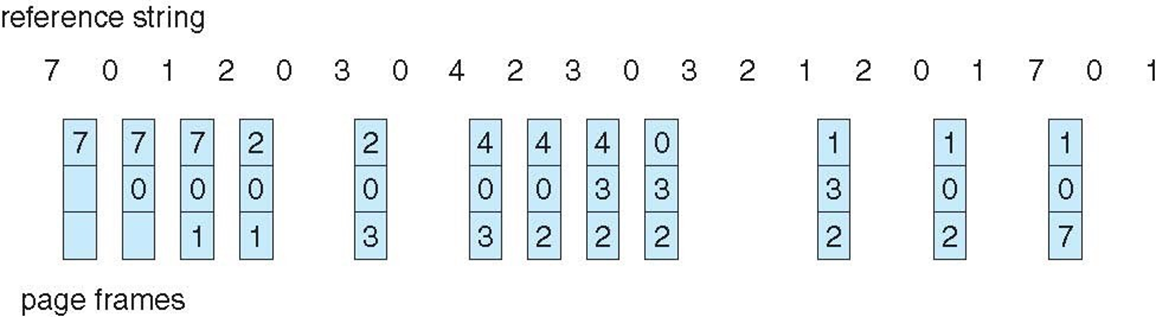
- 처음 다섯번의 부재는 최적 교체와 동일함.
- 근데 페이지 4를 참조하면 LRU 교체의 입장에서는 메모리의 세 프레임 중 페이지 2가 가장 최근에 덜 사용되었으므로 페이지 2가 앞으로 사용될지에 대한 정보 없이 페이지 2를 교체함.
- 다음엔 페이지 2에 대한 부재가 발생해 메모리의 세 페이지 중 가장 최근에 덜 사용한 페이지 3을 교체함.
이런 식으로 진행한다.
LRU 알고리즘은 총 12번의 page fault가 발생함.
최적 알고리즘 보다는 안 좋지만.. FIFO 교체보다 세 번이나 덜 발생함!!
따라서 일반적으로 좋은 알고리즘이며, 자주 사용된다.
■ LRU 구현
그러면 어떻게 LRU를 구현할까?
LRU 페이지 교체 알고리즘은 하드웨어로부터 추가적인 지원이 좀 필요할 수도 있음.
가장 최근에 사용한 시간에 따른 프레임 순서를 어떻게 정의하는지에 대한 방법임.
- Counter로 구현
- 각 페이지 테이블 엔트리가 counter 값(언제 사용했는지에 대한 시간)를 갖고 있도록 하는 방식
- 페이지가 참조될 때마다 시간값을 counter에 저장하도록 한다.
- 페이지 교체가 필요할 때, counter 값이 가장 작은 페이지를 선택한다.
단점:
- 시간을 나타내려면 추가적인 메모리가 꽤 필요함
- 참조할 때마다 시간 정보를 통해 뭘 교체할지 찾아야 하므로 오버헤드가 크다. - Stack으로 구현
- 페이지 넘버 스택을 관리하는 방식.
- 페이지가 참조될 때마다 스택에서 제거한 후 가장 위에 올려놓음.
- 페이지 교체가 필요할 때, 스택의 가장 밑에 있는 페이지를 교체하면 됨.
장점:
- 교체할 페이지를 바로 찾을 수 있음
단점:
- 업데이트하는 과정을 OS가 계속 관리해줘야 해서, 비용이 비싸다.
ex)
Stack 방식을 사용할 때, 페이지 참조시 Stack의 변화를 보자.


포인터가 엄청 많이 바뀌어야 한다. 보다시피 관리 시 비용이 크다!!!
◆ LRU Approximation Algorithms
실제 LRU 페이지 교체를 하드웨어적으로 충분히 지원해주는 컴퓨터 시스템이 그리 많지 않음. 심지어 아예 하드웨어 지원을 안해서 다른 페이지 교체 알고리듬(FIFO 알고리듬)을 사용해야하는 시스템도 있음.
실재로 LRU 근사 알고리즘이 어떻게 동작하는지 보자.
■ Reference bit
대부분의 시스템의 경우엔 Reference bit(참조 비트)를 통해 일종의 지원을 해줌.
페이지 테이블의 각 엔트리에 참조 비트가 존재함.
참조 비트는 페이지 테이블의 각 엔트리에 있음.
초기엔 운영체제가 모든 비트를 (0으로) 비워줌.
프로세스가 실행되면서 하드웨어에서 페이지가 참조되면, 해당 페이지의 참조 비트를 (1로) 설정해줌.
참조 비트를 사용하면 정확한 사용 순서는 모르지만, 어떤 페이지가 사용된 페이지고 어떤 페이지가 사용되지 않은 페이지인지는 알 수 있음. 이런 정보가 LRU 교체를 근사하는 페이지 교체 알고리즘의 기본이 됨!!
■ Second-Chance 알고리즘
Reference bit를 활용한 교체 알고리즘의 예시.
방법은 다음과 같다.
- 페이지가 접근될 때마다 Reference bit를 1로 바꿈.
- 일반적으로 FIFO로 교체함. 그런데 교체할려고 봤는데, Reference bit가 1이다?
→ 바로 교체하지 않고 한번 더 기회를 줌. 0으로 바꾸고 넘어감. - 그러다가 0인 애를 만나면 그때 replacement함.
- 자주 사용하는 페이지의 경우 참조 비트가 계속 1로 재설정될테니 교체당하지 않을 것임.
이 알고리즘을 구현하는 방법 중 하나는 원형 큐임.

- 다음으로 교체할 페이지를 가리키는 포인터(next victim)가 있음.
- 프레임이 필요할 때, 포인터가 참조 비트가 0인 페이지를 찾을 때까지 다음 페이지로 진행하는 것임.
진행하면서 참조 비트를 0으로 바꿔줌. - 참조 비트가 0인 페이지를 발견하면 그 페이지를 교체함.
◆ Global vs Local Replacement
페이지 교체시 어느 범위에서 교체할 것을 찾지에 관한 내용임.
ㆍGlobal Replacement
: 전체 프레임 내에서 Replacement
- 다른 프로세스의 프레임을 뺏어올 수 있음.
- 장점: 기본적으로 Throuput(단위시간당 처리량)이 좋다.
- 단점: 프로세스 마다의 실행 시간이 굉장히 많이 달라질 수 있다.
ex)
프로세스1만 있을 때는 page fault가 별로 안 나고 잘 실행할 수 있었을텐데,
프로세스2가 하나 더 들어와서 메모리를 많이 잡아먹으면 프로세스1이 프레임을 거의 다 뺏길수도 있다.ㅠㅠ
그러면 page fault가 많이 나서 핸들링에 많은 시간 걸릴수있음
ㆍLocal Replacement
: 각 프로세스가 갖고있는 프레임들 내에서 Replacement
- 장점: 프로세스 마다의 퍼포먼스는 일정할 것.
- 단점: 비효율적일 수 있다.
ex)
프로세스1은 메모리 많이 받아놓고 안 쓰는데, 프로세스2는 메모리 부족해서 고생하고 있을 수도 있음.
◆ Thrashing
프로세스 실행중에 page fault가 많이 나서, CPU 사용율이 급격히 떨어지는 상태를 의미함.
프로세스가 실행하는 데 충분한 프레임을 할당받지 못했으면, page fault가 많이 발생해서 CPU utilization이 떨어질 수 있다.
이런 I/O burst에서 page fault가 많아지면 자연스레 CPU burst 시간은 별로 못쓰게 됨
→ 그런데 문제는, OS입장에서 CPU burst가 낮아지면, CPU가 별로 일 안하네? 하고 더 많은 프로세스를 넣어버릴 수도 있음. 그래서 Thrashing이 시작되면 상황이 더 악화될 수도 있음.

따라서 OS는 스레싱이 발생했는지 판단하고,
스레싱이 발생했다고 판단된다면 프로세스를 멈추거나 swap하거나 하는 방식으로 스레싱을 해결하려고 노력해야 함.
→ Locality model 또는 Working-Set model 등을 통해 스레싱을 정의할 수 있다.
■ Locality model
스레싱을 정의하는 모델의 일종.
시간에 따라서 메모리의 어떤 부분이 접근되었는지 보여주는 그림.

- 시간이 지남에 따라 locality(각 프로세스가 사용하는 메모리의 양)가 바뀜.
- 이 모델을 사용해서 언제 스레싱이 발생하는지 알 수 있다.
- 모든 프로세스의 locality 사이즈를 더한 값이 total memory 사이즈보다 큰 경우스레싱이 발생하는 것임
■ Working-Set model
스레싱을 정의하는 모델의 일종.
다음 개념들을 활용해 스레싱이 발생했는지 정의한다.
- Working-Set Window
: 고정된 크기의 페이지 참조 수
- 우리가 관심있게 볼 instruction의 개수를 의미함
- 예를들어 윈도우를 10000으로 잡으면, 메모리 레퍼런스의 개수를 10000개 단위로 끊어서 보겠다는 것.
- 즉 최근 10000개의 instruction만 확인하겠다는 거 - WSS_i
: 프로세스 P_i의 Working Set Size를 의미함.
- Working-Set Window 안에서 최근에 얼마나 많은 페이지들이 참조되었는지에 관한 숫자
- 겹치는 건 빼고, unique한 윈도우 개수를 세는 것
- 이를 통해 Reference당 얼마나 많은 접근이 일어났는지를 평가할 수 있을 것임.- Working-Set Window 가 너무 작으면, 너무 짧은 시간만 보니까 locality를 잘 대변할 수 없고
- 너무 커도 너무 긴 시간을 보니까 locality를 잘 대변할 수 없음.
- 따라서 Working-Set Window 사이즈를 적당히 잘 잡는 게 중요함
- D
: 모든 프로세스의 WSS의 합을 의미함. 즉 모든 프로세스들이 원하고있는 프레임의 개수의 합을 의미함.
- locality의 근사
전체 메모리 사이즈를 m이라 하자.
만약 어떤 시점에서 D > m인 경우, 스레싱이 발생한 것. 프로세스들이 원하는 메모리 양이 전체 메모리보다 큰 거니까.
ex)
Working Set Model을 사용하는 예시를 보자.
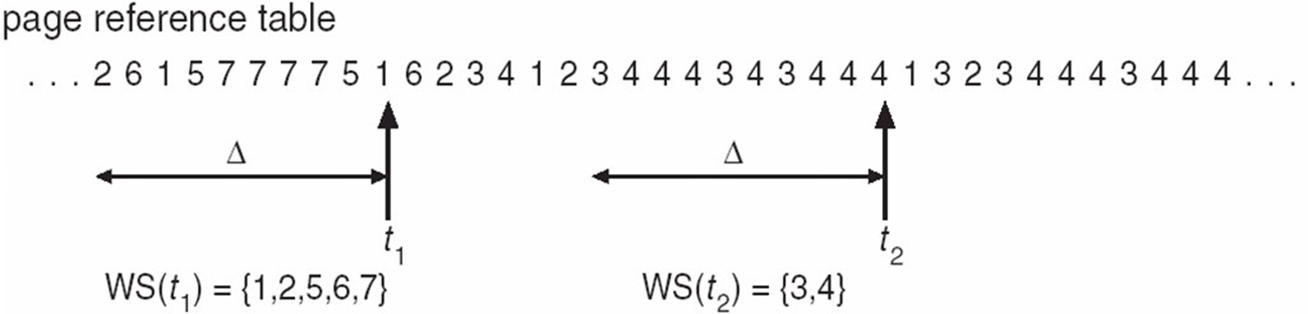
어떤 프로세스가 t1에서는 5개의 프레임을 원하는 거고, t2에서는 2개의 프레임을 원한다는 의미.
이런 식으로 어떤 한 시점에서의 각 프로세스 별 WSS들을 모두 합쳐서 스레싱인지 판단하는 거임.
◆ Page-Fault Frequency (PFF)
Page Fault의 발생 빈도를 체크하면서, 일정 수준을 넘을 수 없도록 하는 것.
이 방식은 Page Fault의 발생 빈도를 체크하면서, 일정 수준을 넘을 수 없도록 하는 것.
일정 수준 ← 이걸 잘 설정하는 게 중요함.
- Page fault rate이 너무 작으면, 할당받은 것보다 더 적게 썼다는 거니까 할당한 거 쫌 뺏음
- Page fault rate이 너무 크면, 프레임이 너무 부족한 거니까 새 프레임들 할당해줌.
※ 기본적으로 이 방법은 Local replacement policy를 가정하고 하는 방법임.
결국 page replacement의 목표는 page fault rate를 줄이는것이므로,
이 방식은 WSS모델에 비해서는 좀 더 직접적인 방식이라 할 수 있음.
ex)
PFF를 사용하는 예시를 보자.

- page fault 비율이 upper bound(상한치)보다 높으면 메모리가 부족한 거니까 더 할당해주고
- page fault 비율이 lower bound(하한치)보다 낮으면 메모리가 충분한 거니까 뺏음
◆ Allocating Kernel Memory
지금까지 유저 메모리가 어떻게 할당되는지 살펴봤다.
- Paging 또는 Demand Paging은 User Process 할당을 위한 것이였다.
그런데 Kernel도 메모리가 필요하고 이에 대해서 할당할 방법이 필요하다.
커널 메모리는 유저 메모리와는 다른 방식으로 할당이 된다.
보통 커널 메모리는 free-memory들의 풀로부터 메모리를 할당받는다.
커널 메모리에 페이징을 적용할 수는 없다.
왜냐면, 메모리 사이즈가 다양하며, 연속적이어야 하는 메모리도 있기 때문.
- 커널은 기본적으로 다양한 사이즈의 메모리를 보관해야 하기 때문에, 메모리를 dynamic하게 요청을 하게 된다.
ex) 프로세스가 만들어지면 이에 해당하는 PCB도 만들어줘야 하고, 그러면 새로운 메모리가 또 필요하게 됨. - 어떤 커널 메모리는 무조건 contiguous하게 저장되어야 하는 경우가 있다!
ex) device I/O를 위한 메모리 등.
커널 메모리 할당 방식으로 두 가지 방식이 존재한다.
- Buddy System Allocator
- Slab Allocator
하나하나 살펴보자.
◆ Buddy System Allocator
메모리를 항상 2의 제곱 단위로 할당하고 관리하는 방식.
- 큰 메모리 청크들을 반복적으로 이등분하여 작은 청크들을 만들며, 가능할 때마다 인접한 빈 청크들을 합치는 과정을 반복하는 기법이다. 청크가 나누어 질 때, 각각이 서로의 버디라고 불린다.
- 고정 분할이나 동적 분할의 단점을 해결하려는 적절한 방법으로 Unix의 Kernel Memory Allocation에서 응용된다.
- External Fragmentation을 없애기 위해서 사용된다.
- 장점: 쪼갰던 청크들을 묶으면 다시 2의 제곱이 되니까, 관리가 편해짐.
- 단점: 지정된 사이즈로 할당해주는 것이기 때문에, 그 사이즈보다 작으면 남는 메모리가 됨. (내부 파편화)
ex)
256 KB 의 메모리 청크(한 덩이)가 있는데, 21 KB 메모리를 요청받았다고 하자.
메모리를 어떻게 쪼개서 할당해줘야 할까?

- 우선 256을 반으로 쪼갬. (128)
- 한번 더 쪼갬. (64)
- 한번 더 쪼갬. (32. 한번 더 쪼개면 21보다 작아지니까 이제 그만.)
- 그리고 나서 32 KB 를 할당해줌.
- 만약 68 KB 를 또 요청받은 경우, 아까 쪼갰던 128 KB 를 할당해줌. (내부 파편화 ㅠ)
쪼개는 경우 항상 자신과 같은 사이즈의 친구(buddy)가 생긴다~
◆ Slab Allocator
사용할 Object들을 크기별로 캐시에 미리 할당해놓 방식.
- Slab: 물리적으로 contiguous한 페이지들의 묶음. (페이지보다 좀 더 큰 단위임. 고정된 사이즈는 아님.)
- Cache: 여러 개의 Slab으로 이루어져 있음
커널에서는 사용하는 자료 구조는 굉장히 다양함 (PCB 등). 이를 통틀어서 Object라고 함.
근데 유저 프로세스랑은 다르게, 한번 자료 구조가 적용이 되면 새로운 게 들어올 일은 없다. 미리 다 정의되어 있는거임.
그래서 같은 크기의 Object들에 대해서, 캐싱을 해놓을 수 있음.
PCB 1, PCB 2… 이런식으로 빈 자료 구조들을 캐시에다 미리 할당하는 것.
그러다가 실제로 프로세스가 만들어져서 PCB가 필요해면, 빈 PCB들 중에 하나 골라서 꺼내주는 방식.
- 캐싱된 자료 구조가 사용되게 되면 used로 표시
- 프로세스 종료되거나 사용하지 않으면 하면 free로 표시
- 장점: 우리가 쓰고자 하는 자료 구조 만큼의 사이즈를 미리 할당해놓는 거니까 fragmentation이 있을 수 없다.
메모리 요청도 빨리 들어줄 수 있다. (새로 메모리 할당을 받을 필요가 없으므로)
ex)
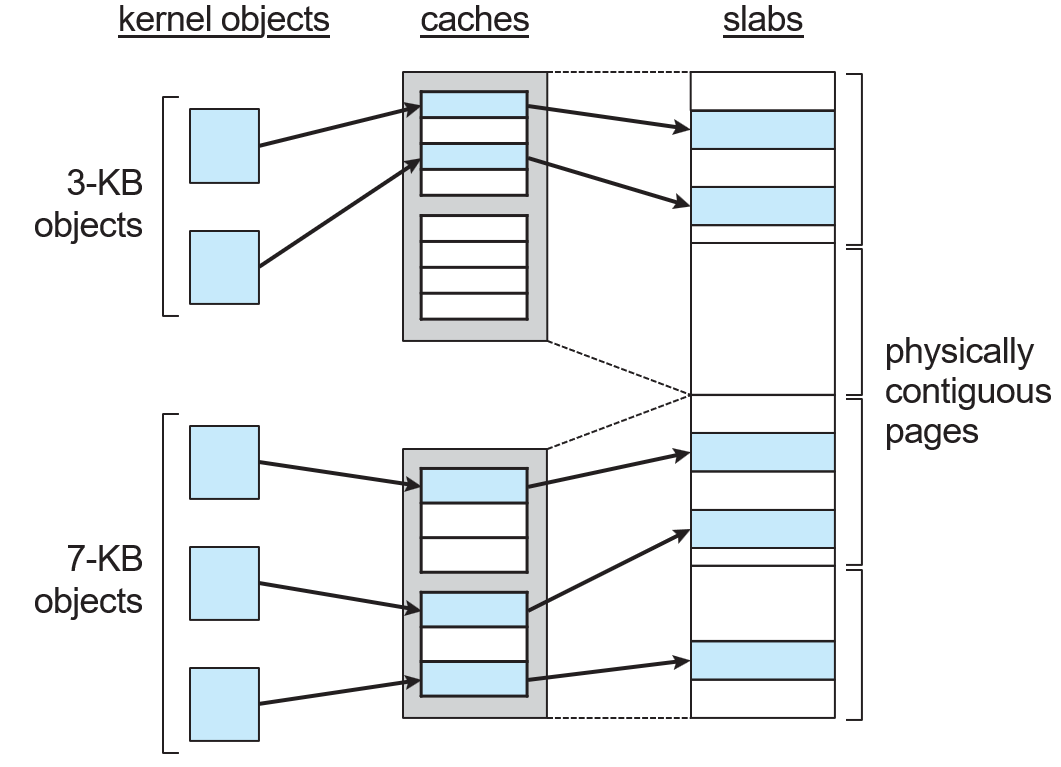
3 KB 크기를 가지는 object들과 7 KB 크기를 가지는 object들 있음.
얘네를 미리 캐시에다 할당함. 캐시는 여러 개의 슬랩들로 구성되어 있음.
각 슬랩은 물리적으로 contiguous한 페이지들의 묶음임. 따라서 contiguous한 메모리 요청도 들어줄 수 있음.
'CS > 운영체제' 카테고리의 다른 글
| 12. I/O System (0) | 2023.12.06 |
|---|---|
| 11. Mass-Storage Structure (0) | 2023.12.05 |
| 9. Main Memory (0) | 2023.12.04 |
| 8. Deadlocks (0) | 2023.10.16 |
| 7. Synchronization Examples (0) | 2023.10.16 |



