
센로그
8. HTTP/2 본문
◆ HTTP/1.1의 문제점
HTTP/1.1은 팀 버너스 리가 대학 및 연구기관들 끼리의 연구 자료를 주고받기 위해 고안한 게 시초이다.
따라서 사진이나 음성, 텍스트 등을 주고받는 게 원래 목표였다.
그런데 인터넷이 폭발적으로 성장하면서, HTTP는 더이상 학술 자료 공유의 목적으로만 쓰일 수는 없었다.
일반인들에게 배포되고, 사용자와 사용량이 늘어나고..
→ 원래 의도하지 않은 방향으로 사용이 되면서 결국은 오리지널 설계 철학에 미처 담지 못한 것들이 문제가 되었다. 주로 성능상의 문제.
대표적인 문제로
- Head of Line (HoL) blocking
- Fat message headers
- Limited priorities
- Client-driven Transmission
가 있다.
◆ Head of Line (HoL) blocking
HTTP/1.1은 머리가 통과하지 못하면 몸통과 꼬리도 통과하지 못하도록 작동함

줄이 있는데 앞 사람이 문제가 발생해서 지연되면, 뒤쪽도 다같이 아무것도 못하고 지연되는 것.
HTTP/1.1은 request받은 순서대로 response을 보내므로, 앞쪽에서 response 작성에 문제가 생기면 뒤쪽 request들에 대한 response는 준비가 되었더라도 전송 못하고 블록됨.
◆ Fat message headers
HTTP/1.1은 뚱뚱한 메시지 헤더를 요청 시마다 주고받아야 했음.
헤더에는 많은 메타 정보들을 포함함.
즉 인간에게 편했던, 인간이 읽을 수 있도록 만들어졌던 메타 정보들을 굉장히 많이 주고받음
요청 시마다 중복된 헤더 값을 전송하게 되며, 포함된 메타정보의 내용도 human-readable하게 설계되어 있어서 값이 커진다. 또는 쿠키 정보도 요청시마다 헤더에 포함되어 전송하므로, 불필요한 부하가 너무 커진다.
ex)
- 200이라 썼으면 됐지 왜 OK를 또 보냄?
- 그리고 200보낼거면 8비트면 보낼거 왜 굳이 유니코드로 커다랗게 보냄?
- 매 요청시마다 중복된 헤더 값을 전송하게 되어 있음. 아파치 서버인 거 한번만 알려주면 되지 매번마다 말해야 함?
- 이외에도 쿠키(웹 브라우저에서 HDD나 SSD에 저장할 수 없기 때문에 웹 브라우저 안의 작은 공간에 저장하는 거)들도 헤더에 엄청 포함해서 주고받음
◆ Limited priorites
HTTP/1.1은 요청들에 대해서 우선 순위의 개념이 없다. 그냥 모두 순서대로 응답함.
그러나 우선순위에 따른 스케쥴링이 필요한 상황들이 등장한다.
예를들어 빨리 데이터가 제공이 안되면 고객이 나가버리니까, 고객이 필요로 하는 거 먼저 보내주면 좋을 것임.
그래서 꼼수를 부리긴 함.
- 이미지 스프라이트: 이미지를 나눠서 흐릿한 이미지라도 일단은 빨리 보낸 후에 점차 또렷한 이미지로 보내주는 방식
그래도 결국 HTTP/1.1은 우선 순위를 제공하는 데 제한이 있다.
◆ Client-driven Transmission
전형적인 클라이언트-서버 구조.
HTTP/1.1은 클라이언트가 요구하지 않은 정보를 서버가 보내는 것은 불가능하다.
그런데 가끔은 서버가 먼저 클라이언트에게 정보를 보내면 편리하게 쓸 수 있는 상황이 있음.
- 주소창에 뭐 조금만 치려고 하면 최근에 접속했던 사이트 도메인 바로 갖고오는 방식 등
그래서 이를 지원하기 시작한 게 HTTP/2
◆ Google SPDY (Proprietary Solution)
웹 콘텐츠 전송을 위해 구글이 개발한 비표준 네트워크 프로토콜
구글의 개발자가 HTTP1.1의 문제점을 개선해보자! 한 것

- TCP/IP위, HTTP 아래에 SPDY를 끼워넣음
(TLS는 암호화계층)
SPDY는 HTTP1.1의 문제점을 두 가지 지적하고 개선하고자 했다.
- 성능
특히 전송 지연. HoL 블록킹 등 TCP의 고질적인 문제점을 개선하고자 함 - 보안
구글 내부의 웹 브라우저 - 서버 사이의 암호화된 통신을 하도록 함
→ Proxy 서버가 패킷 더이상 못 까봄.. 그래서 통신사나 회사 입장에서 안 좋아했음. 회사들이랑 구글이랑 싸우는 일의 시발점
◆ HTTP/2의 주요 목표
- 지연 시간 단축
- HTTP 헤더 필드 압축을 통한 프로토콜 오버헤드 최소화
- 응답 다중화 지원
- 요청 별 우선순위 지정을 추가
- 서버 푸시 지원
- 클라이언트 요청 없이도 서버가 미리 클라이언트에게 도움될만한 정보를 내려보내는 기능을 제공
그리고 기존 HTTP/1.1에서 돌아가던 서비스들에 대해서도 별다른 수정 없이 문제 없이 돌아가도록 지원해준다.
◆ HTTP/1.2가 아닌 HTTP/2인 이유
HTTP/2의 모든 성능 향상의 핵심에는 클라이언트와 서버 간의 HTTP 메시지를 캡슐화하고 전송하는 방법을 위한 새로운 계층 덕분이다. 바로바로
Birary framing layer
- text 기반으로 되어있던 HTTP 메시지를 binary 형태로 된 메시지 포멧으로 바꿈. (bit 단위)
- 메시지 포멧은 HEADERS 프레임과 DATA 프레임으로 나뉘어져 있음
- 단, 기존에 있는 걸 그렇게 변환하는 레이어를 둬서, 상위 계층에서는 여전히 글자들로 쓰고, 전달할 때만 binary로 전달.

더 이상 human-readable 하지 않게, 전송 레벨을 0과 1의 비트 레벨에서 정의하기 때문에 1.2라고 얘기하지 않고 2라고 바꿨다고 함~
◆ Binary Framing Layer
기본적으로 HTTP/2는 HTTP/1.1의 서비스를 다 할 수 있음.
GET, PUT, POST, DELETE 이런거 다 할 수 있다는 뜻.
그래서 기본적으로 HTTP 1.1에서 정의했었던 메소드, 헤더 등의 문법이 HTTP/2에서도 그대로 쓰임.

다만 차이점은 HTTP/2에서 정의한 바이너리의 형태로 변하는 것임.
그래서 그림과 같이 원래 있었던 메시지가 이제 0과 1의 조합의 형태로 만들어져 있는 프레임으로 바뀔 것.
이때 메시지가 프레임들로 나뉘어서 송수신이 된다.
또한 메시지 내부적으로도 헤더 프레임과 데이터 프레임으로 구분함.
- 헤더에 해당하는 것들은 헤더 프레임으로 실어나르고,
- 데이터에 해당하는 건 데이터 프레임으로 실어나름
따라서 HTTP 1.1의 req/resp에 있었던 수많은 메소드들(GET, PUT, DELETE, POST 등)은 다 존재해서 애플리케이션 레벨에서는 이거를 기존처럼 이해하면 되고, 네트워크 레벨에서 주고받을 때에만 HTTP/2의 0과 1의 형태로 바꾸는 것이다.
◆ Stream, Message & Frame
HTTP/2에 등장하는 기본적인 용어들에 대해 다뤄볼 것이다.
HTTP/2에서는 HTTP/1.1에서의 '메시지'를 기준으로 하위 계층에서도, 상위 계층에서도 변화가 일어난다.
- 메시지 하위 계층쪽의 변화:
- 메시지를 프레임 단위로 쪼갬.
- 한 메시지가 헤더 프레임 - 데이터 프레임으로 쪼개짐
- 데이터 사이즈가 큰 경우, 여러 개의 데이터 프레임으로 쪼개져서 전송됨
- 메시지를 프레임 단위로 쪼갬.
- 메시지 상위 계층쪽의 변화:
- 메시지들을 그룹핑해서 구분하는 스트림이라는 개념이 생김
- 어떤 request가 있으면 그에 대한 response(들)가 있을 텐데, 이 쌍을 스트림이라고 부름.
- 이를 통해 순서 없이도 어떤 response가 어떤 request에 대한 response인지 구분할 수 있게 됨.
- 메시지들을 그룹핑해서 구분하는 스트림이라는 개념이 생김
예시를 보자.

- Stream 1에서, Request 메시지를 전송한다.
- index.html을 GET하고자 함.
- 따로 더 들어갈 데이터는 없으니 데이터 프레임 없이 헤더 프레임만 전송함.
- 이에 대한 Response 메시지 또한 Stream 1에서 전송된다.
- 데이터가 포함되어 있으니, 헤더 프레임 뒤에 데이터 프레임이 따라온다.
- 만약 데이터 사이즈가 클 경우, 여러 개의 데이터 프레임으로 쪼개져서 전송된다.
- 이를 하나의 TCP 연결 위에서, Stream 1부터 Stream N까지 동시다발적으로 진행한다.
- 만약 메시지 하나의 사이즈가 크더라도, 여러 프레임으로 쪼개졌기 때문에 연결을 혼자 독점하지는 못함.
쪼개진 메시지를 전송하는 중간 중간에 다른 프레임들도 조금씩 갈 수 있는 것! (원래라면 아예 block됨. HoL Block)
- 만약 메시지 하나의 사이즈가 크더라도, 여러 프레임으로 쪼개졌기 때문에 연결을 혼자 독점하지는 못함.
정리.
- 스트림: 구성된 연결 내에서 전달되는 바이트의 양방향 흐름이며, 하나 이상의 메시지가 전달될 수 있음
- 각 스트림에는 양방향 메시지 전달에 사용되는 고유 식별자와 우선순위 정보(선택 사항)가 있음
- 메시지: 논리적 요청 또는 응답 메시지에 매핑되는 프레임의 전체 시퀀스임
- 각 메시지는 하나의 논리적 HTTP 메시지(예: 요청 또는 응답)이며, 하나 이상의 프레임으로 구성됨
- 프레임: HTTP/2에서 통신의 최소 단위이며, 각 최소 단위에는 하나의 프레임 헤더가 포함됨.
이 프레임 헤더는 최소한으로 프레임이 속하는 스트림을 식별함- 프레임은 통신의 최소 단위이며 특정 유형의 데이터(예: HTTP 헤더, 메시지 페이로드 등)를 전달함. 다른 스트림들의 프레임을 인터리빙한 다음, 각 프레임의 헤더에 삽입된 스트림 식별자를 통해 이 프레임을 다시 조립할 수 있음
- HTTP/2에서 모든 통신은 단일 TCP 연결을 통해 수행되며, 전달될 수 있는 양방향 스트림의 수는 제한이 없음
※ 인터리빙?
큰 정보를 잘게 쪼개서 보내는 동안 그 사이에 끼워넣는 것.
한 요청의 처리과정에 다른 요청을 끼워넣을 수 있다는 의미이다.
좀더 구체적으로 하나씩 알아보자.
◆ 요청 및 응답 다중화
여러 요청 및 응답을 동시다발적으로 수행할 수 있도록 하는 것
HTTP/1.1에서 존재하던 큰 문제 중 하나: HoL Blocking
이를 해결하기 위해 address sharding 등 다양한 꼼수들이 등장했었다.
- address sharding: 여러 개의 도메인 이름을 통해 TCP 연결을 여러 개 뚫어서 동시에 전송할 수 있도록 하는 것
그러나 TCP 연결 하나를 뚫는다는 건 (필수불가결하게) CPU와 메모리를 굉장히 많이 소모하기 때문에, 무작정 많이 뚫어버릴 수는 없음. (TCP 통신 하려면 버퍼 열고, 상태 유지하고, 재전송을 위해 끊임없이 정보를 누적하고 업데이트하며, 플로우 컨트롤 하고...)
따라서 HTTP/2에서는 다른 방법으로 이 문제를 해결하고자 한다.
→ HTTP/2의 Binary framing layer은 요청 및 응답의 다중화를 지원한다.
- 전체 요청 및 응답 다중화를 지원함
- 클라이언트와 서버가 HTTP 메시지를 독립된 프레임으로 세분화하고, 이 프레임을 인터리빙한 다음, 다른 쪽에서 다시 조립함

그림에서 클라이언트는 DATA 프레임(스트림 5)을 서버로 전송 중인 반면, 서버는 스트림 1과 스트림 3의 인터리빙된 프레임 시퀀스를 클라이언트로 전송하고 있다. 3개의 병렬 스트림이 존재하는 것.
이런 다중화의 효과는 다음과 같다.
- 여러 요청을 하나도 차단하지 않고 병렬로 인터리빙 할 수 있음
- 여러 응답을 하나도 차단하지 않고 병렬로 인터리빙 할 수 있음
- 단일 TCP 연결을 사용하여 여러 요청과 응답을 병렬 전달 할 수 있음
- 연결된 파일, 이미지 스프라이트 (image sprites), 도메인 분할과 같은 불필요한 HTTP/1.x 임시 방편을 제거함
이렇듯 요청 및 응답 다중화를 통해 불필요한 지연 시간을 제거하고 가용 네트워크 용량의 활용도를 개선하여 페이지 로드 시간을 줄임
→ 결론적으로, HTTP/1.x에서 발생하는 문제인 HOL(Head-of-Line) 차단을 해결할 수 있으며, 여러 개의 TCP 연결이 없어도 요청 및 응답의 병렬 처리와 전달을 지원할 수 있음. 따라서 애플리케이션이 더 빠르고 단순해지고 배포 비용(서버쪽 부하)이 절감함!!
◆ 스트림 우선 순위 지정
필요에 따라 각 스트림에 우선 순위를 줄 수 있음.
이를 통해 클라이언트가 가장 궁금해할 것을 먼저 전달하고, 관심 없는 부분은 천천히 전달하는 게 가능해짐.
특정 리퀘스트에 대한 리스폰스를 다른 애들보다 먼저 주기 위해서 다음 두 가지 방법을 사용함
- 종속성 (dependancy)
- 어떤 리소스는 먼저 준비되더라도 다른 리소스가 완료될 때까지 기다려야 하는데, 이때 선후 관계가 사용된다.
- css 응답이 먼저 가더라도 html 응답이 와야 사용할 수 있음.
- 스트림별로 다른 스트림에 대한 종속성 부여 가능
- 어떤 리소스는 먼저 준비되더라도 다른 리소스가 완료될 때까지 기다려야 하는데, 이때 선후 관계가 사용된다.
- 가중치 (wating factor)
- 중요한 요청이나 클라이언트가 더 관심있어하는 요청을 비교적 더 빨리 응답해주고자 할 때 가중치가 사용된다.
- 유튜브의 경우 다른 영상의 썸네일이나 설명보다 현재 요청한 영상을 더 빨리 보내고자 함.
- 스트림별로 1~256 사이의 정수 가중치를 할당할 수 있음
- 중요한 요청이나 클라이언트가 더 관심있어하는 요청을 비교적 더 빨리 응답해주고자 할 때 가중치가 사용된다.
◆ 스트림 우선 순위 지정 방법
누가 먼저고 누가 그 후인지에 대한 종속성.
- 스트림의 종속성 및 가중치 조합을 이용하여 클라이언트가 '우선순위 지정 트리'를 구성하고 통신할 수 있음
- 이 트리는 클라이언트가 선호하는 응답 수신 방식을 나타냄
- 서버는 클라이언트가 전달한 우선순위 지정 트리를 통해 CPU, 메모리 및 기타 리소스의 할당을 제어함으로써 스트림 처리의 우선순위를 지정함
- 응답 데이터가 있는 경우, 서버는 우선순위가 높은 응답이 클라이언트에 최적으로 전달되도록 대역폭을 할당함
트리 구조에서, 우선순위가 높은 애들 이런 애들이 이제 상위 요소로 위쪽에 올라가고, 우선순위가 낮은 애들이 하위로 들어감.
만약에 나한테 이제 상위 요소라고 얘기할 애가 없다? 그러면 이제 최상위에 올라온 것.
각 그림 동작 예시. 왼쪽에서부터 1번 경우
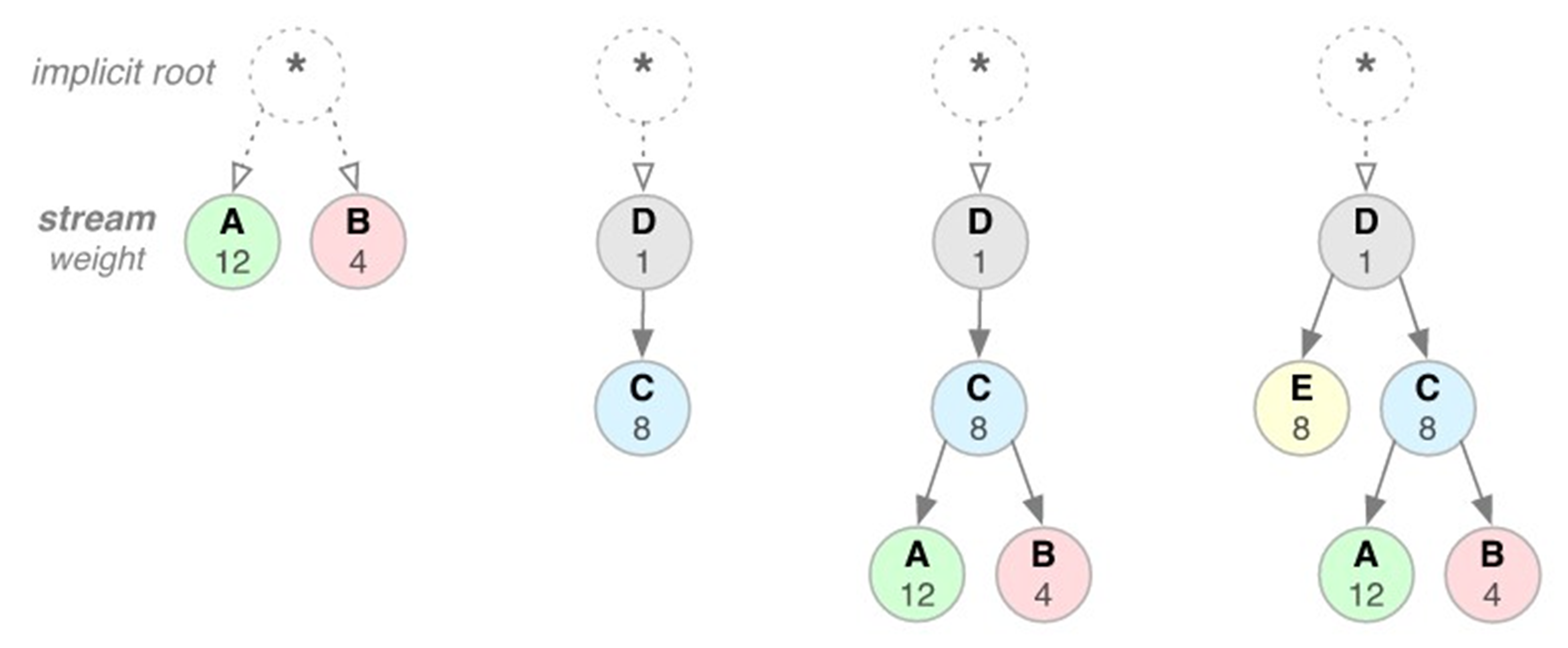
- 스트림 A나 스트림 B는 상위 요소 종속성을 지정하지 않고 암시적 '루트 스트림'에 종속됨. 스트림 A는 가중치가 12이고 B는 가중치가 4임. 따라서 비례 가중치에 따라 스트림 B는 스트림 A에 할당된 리소스의 1/3을 수신해야 함
- 스트림 D는 루트 스트림에 종속되고 C는 D에 종속됨. 따라서 D는 C보다 먼저 전체 리소스를 할당받아야 함. 가중치는 중요하지 않은데 그 이유는 C의 종속성이 더 높은 우선권을 갖기 때문임
- 스트림 D는 C보다 먼저 전체 리소스를 할당받아야 하며, 스트림 C는 A 및 B보다 먼저 전체 리소스를 할당받아야 하고, 스트림 B는 스트림 A에 할당된 리소스의 1/3을 수신해야 함
- 스트림 D는 E 및 C보다 먼저 전체 리소스를 할당받아야 하고, E 및 C는 A 및 B보다 먼저 똑같은 리소스를 할당받아야 하며, 스트림 A 및 B는 가중치에 비례하여 리소스를 할당받아야 함
- 종속성은 자신 보다 높은 우선 순위인 또 다른 스트림의 고유 식별자를 상위 요소로 참조하는 방식으로 선언됨
- 이 식별자가 생략되면 스트림이 '루트 스트림'에 종속됨
- 스트림 종속성 선언은 상위 요소 스트림이 종속성(상위 요소에 종속된 스트림) 보다 전체 리소스를 먼저 할당 받아야 함을 의미함.
- 동일한 상위 요소를 공유하는 스트림(즉, 동위 요소 스트림)은 그 가중치에 비례하여 리소스가 할당되어야 함
- 예시에서 A와 B의 가중치는 각각 12와 4이므로, A와 B에게 응답할 시간 중 3/4은 A에게, 1/4은 B에게 응답하면 되는 것. A의 1 2 3 보내고, B의 1 보내고, A의 4 5 6 보내고, B의 2 보내고 .. 이런 방식
주의해야 할 점은,
- 스트림의 종속성과 가중치는 전송 기본 설정을 표현하는 것이지 요구사항을 표현하는 것은 아니므로, 특정한 처리나 전송 순서를 보장하지는 않음
- 즉, 클라이언트가 스트림 우선순위 지정을 사용하여 특정 순서로 스트림을 처리하도록 서버에게 강요할 수는 없음
- 이것이 이상하게 보일 수도 있지만, 실제로는 바람직한 동작임. 우리는 우선순위가 높은 리소스가 차단된 경우 우선순위가 낮은 리소스에서 서버 진행이 차단되는 것을 원치 않음
- 수많은 서버를 운영하는 곳인데, 보안상 문제가 될 수도 있는데, 이걸 무조건 따라 줄 필요는 없다.
◆ One {TCP} connection per origin
또 하나 주목할 점은,
결국 이런 동시다발적으로 복수의 스트림을 주고받는 행위를 TCP의 연결 하나를 뚫어놓고 한다는 것.
단일 TCP만을 사용한다. 즉, 클라-서버 사이에 오로지 하나의 TCP 커넥션만 유지하는 것.
- HTTP/1.1처럼 스트림을 병렬로 다중화하는 여러 개의 TCP 연결이 더 이상 HTTP/2에 필요 없음
- 모든 HTTP/2 연결은 영구적이고 출처당 하나의 TCP 연결만 필요함
- 기존에는 URL에 주소 쓰고 엔터키 누르면 연결 요청 하고, 로드할 거 다 하면 연결을 끊었음
- 이제는 영구적임: 클라이언트가 서버에서 처음으로 웹 페이지를 보는 시점 이후로는, 그 안에서 다른 웹 페이지를 열더라도 처음 열었던 TCP 세션을 유지하는 것. 즉, 완전히 다른 도메인으로 접속하는 게 아니면 TCP 연결을 끊지 않는다는 것이다.
- 연결 횟수가 적다는 것은 HTTPS 배포의 성능을 개선하는데 특히 중요함.
- 연결 횟수가 적으면 값비싼 TLS 핸드셰이크(보안을 위해 인증 키 만들고 주고받는 작업. 부하가 큼)가 줄어들고, 세션 재사용이 더 향상되며, 필요한 클라이언트 및 서버 리소스가 감소함
단일 TCP 사용시 개선 사항
대부분의 HTTP 전송은 수명이 짧고 폭주(burstness)하는 반면, TCP는 수명이 긴 대량 데이터 전송에 최적화되어 있음.
둘의 수명 기간이 안 맞아서 HTTP 전송시마다 새로 연결하면 부하가 크고 시간이 오래 걸렸음.
- HTTP/2에서는 동일한 TCP 연결을 재사용하여 각 TCP 연결을 더 효율적으로 사용할 수 있으며, 또한 전반적인 프로토콜 오버헤드를 대폭 줄일 수 있음
- 이제 매번 연결을 끊지 않으므로, 요청 및 응답이 독립적일 필요가 없어짐.
따라서 더이상 HTTP Request/Response들은 독립적이지 않게 된다. 전후 간에 상호 연관성을 가짐. - 이를 활용해서 압축을 구현함.
이전에 이미 보낸 리소스를 또 요청받았는데, 내용이 안 바뀌었다? 그러면 안 보냄(헤더 테이블의 index만 보냄)으로써 프로토콜 오버헤드를 줄임.
- 이제 매번 연결을 끊지 않으므로, 요청 및 응답이 독립적일 필요가 없어짐.
- 또한 더 적은 TCP 연결을 사용하므로 전체 연결 경로(즉, 클라이언트, 중개 장치 및 원본 서버)에서 메모리와 처리량이 줄어듬
- 그 결과 전체 운영 비용이 절감되고 네트워크 활용도와 용량이 개선됨
- 따라서 HTTP/2로 전환하면 네트워크 지연 시간이 줄어들 뿐만 아니라 처리량이 개선되고 운영 비용이 줄어듬
◆ 흐름 제어
HTTP/2로 들어오면서, 스트림 단위로 전송하는 것으로 바뀌었다.
따라서 HTTP/2는 각 스트림별 흐름을 제어할 수 있는 기능을 제공한다.
HTTP/2에서 일반적인 흐름 제어의 개념은 다음과 같다.
- 수신단에서, 송신단의 데이터가 불필요하거나 처리가 불가능한 경우, 수신단에 부담을 주는 것을 막을 수 있음
예를들어 영상 스트리밍을 한다고 하자.
서버에게 영상을 스트리밍 해달라고 하면, 조금씩 내려줌.
유튜브 보면 진행 바에 흰색 부분이 있는데, '버퍼링' 하는것.
미리 영상을 받아둠으로써 네트워크가 조금 지연되더라도 안 끊기고 잘 재생되게 하는 것임
문제는 뭐냐?
영상 끝까지 전부 버퍼링이 된다고 하면, 영상이 끝날 때까지 안 끊기고 잘 감상할 수 있어서 좋을 것임.
그런데 만약 영상 길이만큼 다 받아놨는데, 안보고 나가면? 그냥 헛수고 되는거임.
열심히 보낸 서버도 헛수고, 열심히 받은 클라이언트도 헛수고, 열심히 전달한 네트워크도 헛수고.
따라서 HTTP/2에서의 흐름 제어는, 어플리케이션 입장을 대변하는 흐름 제어이다.
사용자가 일시정지 해놓으면 더이상 버퍼링 안한다거나, 어느정도 수준까지만 버퍼링을 유지한다거나 그런 작업.
HTTP/2 흐름제어의 특징
- 흐름 제어를 구현하기 위한 특정 알고리즘을 지정하지 않음
- 그 대신 간단한 빌딩 블록(기능)을 제공하고 그 구현을 클라이언트와 서버에 넘김
- 그러면 클라이언트와 서버가 이 빌딩 블록을 사용하여 사용자 설정 전략을 구현하여 리소스 사용과 할당을 제어함
- 웹 애플리케이션의 실제 성능과 측정된 성능을 모두 개선할 수 있는 새로운 전달 기능도 구현하도록 지원함
- 예를 들어, 애플리케이션 계층 흐름 제어에서는 브라우저가 특정 리소스의 일부분만을 가져온 후, 스트림 흐름 제어 창을 0으로 줄여서 가져오기를 보류한 다음, 나중에 가져오기를 재개할 수 있도록 허용함
- 즉, 브라우저가 특정 이미지의 미리보기나 최초 스캔을 가져와서 표시할 수 있고, 우선순위가 더 높은 다른 가져오기 동작을 진행할 수 있으며, 더 많은 주요 리소스가 로딩된 후에 가져오기를 재개할 수 있음
HTTP/2 흐름 제어 원리
- 흐름 제어는 양방향임
- 각 수신단은 각 스트림 또는 전체 연결에 원하는 창 크기를 설정하도록 선택할 수 있음
- 흐름 제어는 크레딧 기반임 (윈도우랑 비슷한 개념)
- 각 수신단은 자체의 초기 연결과 스트림 흐름 제어 Window (바이트 단위, 버퍼 크기)을 알림
- 이 Window는 송신단이 DATA 프레임을 방출할 때마다 감소하고,
수신단이 WINDOW_UPDATE 프레임을 보낼 때마다 증가함
- 흐름 제어는 비활성화될 수 없음
전송을 pause하면 흐름 제어를 끈 것이라고 오해할 수 있는데 아님. 흐름 제어 하에서 전송을 중단시킨 것 뿐.
- HTTP/2 연결이 구성되면 클라이언트와 서버가 SETTINGS 프레임을 서로 교환함.
→ 이 프레임은 양쪽 방향에서 흐름 제어 창 크기를 설정함 - 흐름 제어 창의 기본값은 65,535 바이트로 설정되지만, 데이터가 수신될 때마다 수신기가
WINDOW_UPDATE 프레임을 전송하여 최대 창 크기(2^31-1바이트)를 설정하고 유지할 수 있음
- HTTP/2 연결이 구성되면 클라이언트와 서버가 SETTINGS 프레임을 서로 교환함.
- 흐름 제어는 종단간 (End-to-End) 방식이 아니라 홉 (Hop-by-Hop) 방식임
- 흐름 제어가 두 종단 간에만 이루어지는 게 아니라, 그 사이에 거치는 컴퓨터들 사이에서도 이루어진다는 의미이다. 만약 클라이언트와 서버 사이에 프록시 서버가 있어서 '클라이언트-프록시서버-서버 ' 순으로 데이터를 전송하는 경우, 흐름 제어는 '클라이언트-프록시서버', '프록시서버-서버' 이렇게 각각에 대해서 독립적으로 이루어진다.
- 즉, 중개자(intermediary)가 자체적인 기준과 추론에 따라 리소스 사용을 제어하고 리소스 할당 메커니즘을 구현할 수 있음
◆ 서버 푸시
HTTP/1.1에서는 request가 와야 response를 보낼 수 있었음.
그런데 어떤 경우에는 서버가 먼저 클라이언트에게 보내는 경우에 편리성을 제공할 수 있기도 함.
이해를 돕기 위해 이메일 알림 앱의 경우를 보자.
- gmail 앱을 깔면 메일이 도착할 때마다 즉시 알림을 주는 게 가능함.
- 그런데 기본 이메일 앱의 경우, 즉시 알림이 오는 게 아니라 어느정도 후에 알림이 오곤 함.
- 둘의 차이점: gmail 앱은 내가 요청하지 않아도 보내주는 '푸시 메일'을 제공하는 거고, 기본 이메일 앱 같은 경우 일정 시간마다 서버에 '나한테 메일 온 거 있니?' 하고 먼저 요청해서, 있으면 가져와서 알림을 보내주는 것.
여기서 gmail 앱의 경우가 서버 푸시와 유사한 경우라고 볼 수 있다.
HTTP/2에서는 클라이언트가 명시적으로 먼저 요구하지 않아도, 서버가 추가적인 리소스를 클라이언트에게 미리 푸시할 수 있다.
예시를 보자.

stream 1 의 경우 클라가 요청하고 서버가 응답해주는 걸 볼 수 있다.
그런데 stream 2나 stream 4의 경우 프레임에 promise라고 되어있네?!
- promise: 아마도 클라에게 이 리소스가 필요할 것이니, 클라가 요청하지 않더라도 서버가 내려보내겠다고 미리 약속하는 것.
- 사용자의 지연을 줄이기 위한 목적이 큼
'굳이 누르는 시점에 요청해서 실행하기 보다는, 할 것 같은 동작들에 대해서 미리 받아놓으면 빨리 실행할 수 있지 않겠니?' 하는 컨셉임.
- 사용자의 지연을 줄이기 위한 목적이 큼
◆ 서버 푸시 동작
다음 과정을 거쳐서 서버 푸시가 이루어진다.
- 서버가 미리 내릴 스트림들을 판단한다.
- PUSH_PROMISE : 서버가 클라이언트에게 어떤 리소스를 미리 내리겠다고 사전 공지하는 프레임을 의미한다.
푸시할 컨텐츠에 대한 헤더 정보를 포함한다. - 클라이언트는 이를 통해 서버가 내리려고 하는 리소스에 대한 상세한 정보를 알고, 이에 대해 다양한 방식으로 대응할 수 있다.
- 받겠다고 할 수 있다.
- 이미 나한테 있으니 안 받겠다고 할 수 있다. (RST_STREAM)
- 받는데, 동시에 몇 개까지만 받도록 할 수 있다. (동시에 연결할 푸시 스트림의 개수 설정)
- 일부만 받고 안 받을 수도 있다.
- 속도를 조절할 수 있다.
- ...
근데 사실 크롬에서는 서버 푸시 받는 기능을 뺐음.
좋은 기술이나, 구현 난이도가 있어서 쓰는 사람이 별로 없었기 때문.
◆ 헤더 압축
과거와 현재의 차이를 기반으로, 헤더의 내용을 줄이는 것
HTTP/1.1에서는 매번 송수신 시마다 메시지가 독립적으로 오가므로, 헤더에 모든 내용을 매번 때려넣어야 했었다.
헤더에는 불필요한 내용들도 많고, 쿠키도 들어가고, ... 생각보다 되게 커다란데, 매번 주고받기에는 부하가 크다 ㅠ
HTTP/2는 더이상 그렇지 않다. 스트림이라는 논리적 연결을 제공하므로, 이전에 보냈던 프레임에 관한 정보를 기억해둘 수 있다. 이 개념이 헤더 압축의 근간이 되는 개념이다.
HTTP/2 의 표준 압축 기술은 HPACK이라는 HTTP 패킹 기술이다.
이는 허프만 코딩과 헤더 테이블을 사용해 헤더를 압축하는 방식이다.
- 허프만 코딩을 사용해 차이값만 전달할 수 있다.
- 헤더 테이블을 사용해 동일한 스트림(혹은 연결) 안에서, 지금 보낼 스트림의 헤더 정보가 이전에 보냈던 Request(혹은 Response)의 헤더 정보와 달라지지 않았다면 다시 보내지 않고 인덱스만 보내도록 한다.
예시를 보자.

- 첫 리퀘스트 Request #1을 보낼 때 헤더에 다음 정보들을 포함했다.
- GET 리퀘스트이고, HTTPS로 보내며, 목적지 주소는 example.com이고, 리소스를 가져올 url path는 root/resource이다. image를 받고싶은데 jpeg로 받을 것이고, 나는 Mozilla에서 만든 5.0버전 웹 브라우저다.
- 이에 대한 응답을 받았다 하자.
- 다음 리퀘스트 Request #2를 보낸다고 하자. 그런데 Request #1하고 달라진 게 거의 없네?
- 달라진 것에 대해서만 보내자!
- 현재 path가 달라졌으니, 이 정보만 헤더에 실어 나르는 것
HTTP/2에서는 이전에 보낸 프레임의 필드들과 지금 보낼 프레임의 필드들을 비교해서, 다른 값을 가지고 있다면 해당 필드만 보내도록 한다. 새로운 정보나 바뀐 정보만 전달하는 것.
이런 방식으로 동작하려면, 우리는 이런 프레임의 필드 값들이 이전에 전송된 값과 같은지 아닌지를 판단할만한 정보가 필요하다. 이 정보가 테이블로 관리된다.
통상 두 개의 테이블을 쓴다.
- Static Table
- 프로그램 작성시 만들어놓은 필드들.
- 많이 사용될 것 같은 정보들에 대해 미리 테이블에 넣어놓은 것.
- Dynamic Table
- 실제 서비스 시작 시점부터 만들어지는 필드들.
- 통신을 하면서 업데이트되는 정보들이 들어감
예시를 보자.
맨 왼쪽이 보내야 할 정보, 중간이 참조하는 헤더 테이블, 맨 오른쪽이 (압축 후) 실제로 보내지는 정보이다.

다음과 같은 방식으로 동작한다.
- 송신측에서 GET 요청을 하고 싶다.
- Static table에 2번에 이미 GET에 대한 필드가 있다.
- 메서드 자리에 GET을 쓰지 않고, GET의 인덱스에 해당하는 2값을 써서 보낸다.
- 수신측에서 이를 받는다.
- 정보가 주렁주렁 있는 게 아니라 인덱스 값 2만 있네?
- 테이블을 보고, 2를 대체하는 메서드인 GET을 갖고 와서 헤더를 재구성한 후, 요청을 처리한다.
혹은, 다음과 같은 방식으로 동작한다.
- 맨 오른쪽 path 부분에, Huffmann("/resource")라고 적혀있다.
- 바뀐 값이니 인덱스를 안적고 내용물을 적어준 것이다. 그런데 잘 보니, 인덱스(19)도 있네!?
- 이때의 인덱스 역시 기존 정보를 의미한다.
- '내용 전체'를 보내는 것보다, '기존 내용과 바뀐 내용의 차이'를 보냈을 때 데이터 량이 더 줄어들기 때문에, 허프만 코딩을 사용해서 기존과 대비해서 이만큼 바뀌었어~ 하는 정보를 주는 것이다.
- 이런 경우 기존 인덱스와 바뀐 값의 쌍을 보낸다.
- 수신 측에서는 이를 받고, 일단 인덱스 19의 내용물을 꺼낸다.
- 그리고 19번과 대비해서 바뀐 값에 대한 정보를 적용하고, 이로부터 path 정보를 복원한다.
요약하자면 이렇다.
- 많이 주고 받는 정보나 주고받은 적 있는 정보를 테이블에 저장해놓는다.
- 변하지 않은(또는 거의 고정된) 것들은 인덱스만 보낸다.
- 변한 것들에 대해서는 허프만코딩으로 인코딩하여 인덱스 값과 원본과의 차이 값을 쌍으로 보낸다.
- 기존과의 차이 값을 보내는 게 원본을 보내는 것보다 이득이라면, 허프만 코딩을 이용해 인덱스 값과 원본과의 차이 값을 쌍으로 보냄으로써 데이터 량이 줄어든다.
이를 통해 통신 링크 상에서 주고받는 데이터의 상당량이 감소될 것.
그러나 컴퓨터 각자의 프로세싱 파워가 늘어나는 건 어쩔 수 없다...^^
◆ RSA Encryption
RSA 는 현재 SSL/TLS에 가장 많이 사용되는 비대칭형 공개키 암호화 알고리즘이다.
RSA 암호화의 동작 원리를 보자.
RSA는 암호화된 전송을 위해 개인키(private key)와 공개키(public key)를 사용하는 방식이다.
- 개인키: 복호화 시 사용하는 키
- 자신만이 갖는다.
- 공개키: 암호화 시 사용하는 키
- 자신 포함, 다른 사용자들도 가질 수 있다.

다른 사용자에게 암호문을 보내고 싶다면, 상대방의 공개키를 사용해 데이터를 암호화해서 전송한다.
그러면 상대방은 받은 암호문(자신의 공개키로 암호화한 암호문)을 자신의 개인키로 복호화한다.
하나의 키로 암호화/복호화를 진행하기에 키가 유출될 시 보안이 취약해졌던 대칭키 방식과 다르게,
RSA 방식의 경우 공개키는 유출되어도 상관 없다는 장점이 있다. 개인키로만 복호화할 수 있기 때문.
◆ RSA Encryption - HTTP를 이용한 handshake 방식
RSA가 HTTP에서 적용되는 과정을 보자.
- 서버측에서는 OpenSSL을 이용하여 서버에 대한 정보와 인증등이 담긴 인증서와, 공개키를 인증기관(CA)에 등록함.
- 클라이언트는 대칭키(공통키)를 생성하고, 등록되어져 있는 공개키로 대칭키(공통키)를 암호화하여 서버측에 전송함.
- 서버측에서는 클라이언트에서 전송된 암호(공개키로 암호화된)를 개인키를 사용하여 복호화하여 대칭키(공통키)를 흭득함.
- 이제 서버 및 클라이언트는 동일한 대칭키(공통키)를 사용하여 보안 통신을 수행할 수 있음.
◆ TLS기반 HTTP/2 Client & Server 예제
GO 언어 에서는 2016년부터 표준으로 언어의 표준 라이브러리로 HTTP/2을 제공하고 있다.
그래서 GO로 된 예제 코드를 볼 것이다.
HTTP/2 TLS 기반 통신을 하려면, 인증서 파일(.crt)과 키(.key)가 필요하다.
- 웹 서버는 자신이 믿을만한(지속적이고 안전하며 비용도 지불가능한) 서버라는 걸 외부 기관의 인증을 받을 수 있다.
- 서버가 외부 인증 기관에 (OpenSSL 등으로 생성한) 자신의 인증서와 공개키를 등록한다.
- 인증서에는 서버의 정보와 공개키가 들어있다.
- 클라이언트는 인증 단체로부터 이 인증서를 받아서, 서버가 믿을만한지 판단하고 공개키를 사용해 대칭키를 암호화해서 보낸다.
- 서버는 개인키로 암호문을 복호화하여 대칭키를 얻어낸다.
- 이제 서버 및 클라이언트는 동일한 대칭키(공통키)를 사용하여 보안 통신을 수행할 수 있게 된다.
우리 예제에서는, 실제로 외부에서 인증서를 받을 수는 없으므로, 내가 인증 기관처럼 작업을 해줘야 한다.
OpenSSL을 사용하면 로컬에서 사용 가능한 임시 인증서와 임시 암호화 키를 만들 수 있다.
다음 커맨드를 실행하면 됨.
openssl req -x509 -out server.crt -keyout server.key \
-newkey rsa:2048 -nodes -sha256 \
-subj '/CN=localhost' -extensions EXT -config <( \
printf "[dn]\nCN=localhost\n[req]\ndistinguished_name = dn\n[EXT]
\nsubjectAltName=DNS:localhost\nkeyUsage=digitalSignature\nextendedKeyUsage=serverAuth")
서버의 인증서와 키를 서버 코드가 위치한 폴더에 옮겨주자.
그리고 인증서는 클라이언트가 위치한 폴더에도 옮겨주자.
그러면 실행할 준비 끝.
◆ HTTP/2 기본적 서버 코드

- HTTP 프로토콜로 서버를 띄울건데, 내 IP 주소와 포트넘버 800번을 가지고 띄우고, 핸들러로는 http.HandlerFunc(handle)을 쓸 것이다.
- handle은 말 그대로 request가 왔을 때 이를 핸들링해서 response를 만들어주는 애.
- 받은 리퀘스트의 프로토콜과 원격 주소를 화면에 한번 출력해주고,
- http.ResponseWriter를 통해 Hello라는 문자열을 바이트로 써서 response로 보낸다.
- 메인에 보면, srv.ListenAndServeTLS라는 부분이 있다.
말 그대로 서버 실행하는 동작인데, 이때 TLS를 지원하도록 하는 것이다.
(GO에서 HTTP/2를 표준으로 지원하는 만큼 그냥 한줄만에 끝나버린 것.)- 여기에 파라미터를 보면, .crt 파일과 .key 파일을 넘긴다. 아까 만들었던 걔네임.
◆ HTTP/2 기본적인 클라이언트 코드

필요한 모듈들 임포트 해준다.

클라이언트 만들고, TLS 여는 과정.
- caCert에다 cirtification 파일을 읽어온다.
- 원래는 인증 기관에서 키 값을 갖고오려고 할 것임. 우리는 로컬이므로 로컬 파일 사용
- 거기서 cirtification에 대한 정보를 추출하고 풀을 만든다.
- 이를 통해 TLS 레이어를 Configuration한다.
밑에 보면 httpVersion을 바꾸는 부분이 있는데, TLS는 별도로 있는 거고 그걸 HTTP/2가 쓰는 것이기 때문에.,
- HTTP/2라면 당연히 TLS 쓰는 거 가능하고.
- HTTP/1.1이어도 TLS 쓰는 것 가능하다.

◆ 실행 결과


'CS > 풀스택서비스네트워킹' 카테고리의 다른 글
| 10. QUIC & HTTP/3 (0) | 2023.12.08 |
|---|---|
| 9. WebRTC (0) | 2023.12.08 |
| 7. gRPC (0) | 2023.12.08 |
| 6. HTTP/1.1 (0) | 2023.10.16 |
| 5. ZeroMQ (1) | 2023.10.15 |



