
센로그
[RL 실습] Frozen Lake 본문
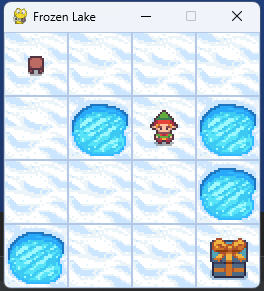
FrozenLake 1단계
import gym
import numpy as np
# FrozenLake-v1이라는 환경을 만들고,
# 미끄러지게 할지 말지 설정
# 사람이 보기 좋은 human 모드로 설정
env = gym.make("FrozenLake-v1", is_slippery = False, render_mode = "human")
# env.reset() : 환경의 state를 초기 상태로 바꿔줌.
# (0, {'prob' : 1}) <- (현재 위치, 다음 상태로 넘어갈 확률)
print(env.reset())
# env.step(action) : 주어진 action에 따라 행동을 한 뒤 다음 상태, 보상, 종료 여부 등을 반환
# (action, 0.0, False, False, {'prob' : 0.33333333})
# action은 정책에 따라 골라질 것. 지금은 랜덤으로 고를 것임. env.action_space.sample()로 랜덤으로 action 고를 수 있음
print(env.step(1))
env.step(env.action_space.sample())
# 화면에 표시
env.render()
FrozenLake 2단계
하나의 에피소드에 대한 경우
env = gym.make("FrozenLake-v1", render_mode = "human")
done = False
history = []
state = env.reset() # (0, {'prob' : 1}) <- (현재 위치, 다음 상태로 넘어갈 확률)
state = state[0]
while not done:
next_state, reward, done, _, _ = env.step(env.action_space.sample())
history.append((state, reward, done))
env.render()
state = next_state #다음 스테이트로 넘어감
여러 에피소드에 대한 경우
env = gym.make("FrozenLake-v1", render_mode = "human")
MAXEPISODENUM = 10
for epi in range(MAXEPISODENUM):
done = False
history = []
state = env.reset() # (0, {'prob' : 1}) <- (현재 위치, 다음 상태로 넘어갈 확률)
state = state[0]
while not done:
next_state, reward, done, _, _ = env.step(env.action_space.sample())
history.append((state, reward, done))
env.render()
state = next_state #다음 스테이트로 넘어감
FrozenLake 3단계
Agent 만들기, Q-table 만들기
import random
import gym
import numpy as np
# FrozenLake-v1이라는 환경을 만들고,
# 미끄러지게 할지 말지 설정
# 사람이 보기 좋은 human 모드로 설정
class QAgent():
def __init__(self):
self.q_table = np.zeros((4,4,4)) #q table. 4x4 배열을 총 4개 만듦.
self.eps = 0.9 # 입실론값 설정.
self.gamma = 0.99
self.alpha = 0.01
def select_action(self, state): # 받아온 state를 바탕으로 본인의 정책을 수정. statem는 0~15
row, col = int(state/4), state%4 # row와 column 형태로 수정
rnum = random.random() #0.0~1.0
if rnum<self.eps: # 뽑은 랜덤 넘버가 입실론보다 낮다면
action = random.randint(0,3) # 랜덤한 액션 설정
else:
action_val = self.q_table[:, row, col] # row, col 위치에서 q table들을 보고 가장 큰 값을 가져온다
action = np.argmax(action_val) # 가장 큰 값의 인덱스
return action
def update_table(self, history):
# history에는 state, reward, n_sate...등이 담겨있을 수 있음.
returnGt=0
for transition in history[::-1]: #뒤에서부터 접근
state, action, reward, n_state = transition
row, col = int(state/4), state%4
returnGt = reward + self.gamma*returnGt # 다음 스텝의 reward + 감마*현재까지Gt
# 현재 채택된 큐테이블 갖고와서 업데이트
self.q_table[action, row, col] = self.q_table[action, row, col] + self.alpha*(returnGt-self.q_table[action, row, col])
def decrease_eps(self):
self.eps -= 0.03
self.eps = max(self.eps, 0.1)
def show_table(self): # 현재 스테이트에서 어느 경로로 가는게 최선인지. action들을 표시
data = np.zeros((4,4))
for s in range(16):
row, col = int(s/4), s%4
data[row,col] = np.argmax(self.q_table[:,row,col])
print(data)
env = gym.make("FrozenLake-v1", is_slippery = False) #render_mode = "human"
agent = QAgent() # agent 만들기
MAXEPISODENUM = 10000
total_reward = 0
for epi in range(MAXEPISODENUM):
done = False
history = []
state = env.reset() # (0, {'prob' : 1}) <- (현재 위치, 다음 상태로 넘어갈 확률)
state = state[0]
while not done:
action = agent.select_action(state)
next_state, _, done, _, _ = env.step(action) # agent가 선택하는 action
reward = -1 # 움직일 때마다 -1
if(next_state == 15): # 15번 위치에 도달하면 리워드 10
reward = 10
elif(next_state == 5 or next_state == 7 or next_state == 11 or next_state == 12): # 구멍에 빠지면 리워드-10
reward = -10
total_reward += reward
history.append((state, action, reward, next_state))
# env.render()
state = next_state #다음 스테이트로 넘어감
agent.update_table(history) # history 업데이트
agent.decrease_eps() # 입실론값 줄이기
if(epi%1000 == 0 and epi != 0):
print(f"{epi}/{MAXEPISODENUM}")
print(total_reward/epi)
agent.show_table()
## test
env2 = gym.make("FrozenLake-v1", is_slippery = False, render_mode = "human")
agent.eps = 0.1
for epi in range(100):
done = False
history = []
s = env2.reset()
s = s[0]
while not done:
a = agent.select_action(s)
n_s, _, done, _, _ = env2.step(a)
s = n_s
FrozenLake - MC(MonteCarlo) Version
import random
import gym
import numpy as np
# FrozenLake-v1이라는 환경을 만들고,
# 미끄러지게 할지 말지 설정
# 사람이 보기 좋은 human 모드로 설정
class QAgent():
def __init__(self):
self.q_table = np.zeros((4,4,4)) #q table. 4x4 배열을 총 4개 만듦.
self.eps = 0.9 # 입실론값 설정.
self.gamma = 0.99
self.alpha = 0.01
def select_action(self, state): # 받아온 state를 바탕으로 본인의 정책을 수정. statem는 0~15
row, col = int(state/4), state%4 # row와 column 형태로 수정
rnum = random.random() #0.0~1.0
if rnum<self.eps: # 뽑은 랜덤 넘버가 입실론보다 낮다면
action = random.randint(0,3) # 랜덤한 액션 설정
else:
action_val = self.q_table[:, row, col] # row, col 위치에서 q table들을 보고 가장 큰 값을 가져온다
action = np.argmax(action_val) # 가장 큰 값의 인덱스
return action
def update_table(self, history):
# history에는 state, reward, n_sate...등이 담겨있을 수 있음.
returnGt=0
for transition in history[::-1]: #뒤에서부터 접근
state, action, reward, n_state = transition
row, col = int(state/4), state%4
returnGt = reward + self.gamma*returnGt # 다음 스텝의 reward + 감마*현재까지Gt
# 현재 채택된 큐테이블 갖고와서 업데이트
self.q_table[action, row, col] = self.q_table[action, row, col] + self.alpha*(returnGt-self.q_table[action, row, col])
def decrease_eps(self):
self.eps -= 0.03
self.eps = max(self.eps, 0.1)
def show_table(self): # 현재 스테이트에서 어느 경로로 가는게 최선인지. action들을 표시
data = np.zeros((4,4))
for s in range(16):
row, col = int(s/4), s%4
data[row,col] = np.argmax(self.q_table[:,row,col])
print(data)
env = gym.make("FrozenLake-v1", is_slippery = False) #render_mode = "human"
agent = QAgent() # agent 만들기
MAXEPISODENUM = 10000
total_reward = 0
for epi in range(MAXEPISODENUM):
done = False
history = []
state = env.reset() # (0, {'prob' : 1}) <- (현재 위치, 다음 상태로 넘어갈 확률)
state = state[0]
while not done:
action = agent.select_action(state)
next_state, _, done, _, _ = env.step(action) # agent가 선택하는 action
reward = -1 # 움직일 때마다 -1
if(next_state == 15): # 15번 위치에 도달하면 리워드 10
reward = 10
elif(next_state == 5 or next_state == 7 or next_state == 11 or next_state == 12): # 구멍에 빠지면 리워드-10
reward = -10
total_reward += reward
history.append((state, action, reward, next_state))
# env.render()
state = next_state #다음 스테이트로 넘어감
agent.update_table(history) # history 업데이트
agent.decrease_eps() # 입실론값 줄이기
if(epi%1000 == 0 and epi != 0):
print(f"{epi}/{MAXEPISODENUM}")
print(total_reward/epi)
agent.show_table()
## test
env2 = gym.make("FrozenLake-v1", is_slippery = False, render_mode = "human")
agent.eps = 0.1
for epi in range(100):
done = False
history = []
s = env2.reset()
s = s[0]
while not done:
a = agent.select_action(s)
n_s, _, done, _, _ = env2.step(a)
s = n_s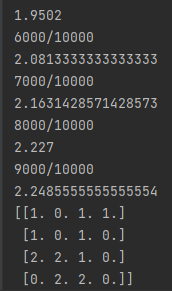
FrozenLake - TD(Temporal Differance) Version
import random
import gym
import numpy as np
# FrozenLake-v1이라는 환경을 만들고,
# 미끄러지게 할지 말지 설정
# 사람이 보기 좋은 human 모드로 설정
class QAgent():
def __init__(self):
self.q_table = np.zeros((4,4,4)) #q table. 4x4 배열을 총 4개 만듦.
self.eps = 0.9 # 입실론값 설정.
self.gamma = 0.99
self.alpha = 0.01
def select_action(self, state): # 받아온 state를 바탕으로 본인의 정책을 수정. statem는 0~15
row, col = int(state/4), state%4 # row와 column 형태로 수정
rnum = random.random() #0.0~1.0
if rnum<self.eps: # 뽑은 랜덤 넘버가 입실론보다 낮다면
action = random.randint(0,3) # 랜덤한 액션 설정
else:
action_val = self.q_table[:, row, col] # row, col 위치에서 q table들을 보고 가장 큰 값을 가져온다
action = np.argmax(action_val) # 가장 큰 값의 인덱스
return action
def update_table(self, history):
# history에는 state, reward, n_sate...등이 담겨있을 수 있음
for transition in history[::-1]: #뒤에서부터 접근
state, action, reward, n_state = transition
row, col = int(state/4), state%4
n_row, n_col = int(n_state/4), n_state%4
n_action = self.select_action(n_state)
# 현재 채택된 큐테이블 갖고와서 업데이트
self.q_table[action, row, col] = self.q_table[action, row, col] + self.alpha * (
reward + self.gamma * self.q_table[n_action, n_row, n_col]
- self.q_table[action, row, col])
def decrease_eps(self):
self.eps -= 0.03
self.eps = max(self.eps, 0.1)
def show_table(self): # 현재 스테이트에서 어느 경로로 가는게 최선인지. action들을 표시
data = np.zeros((4,4))
for s in range(16):
row, col = int(s/4), s%4
data[row,col] = np.argmax(self.q_table[:,row,col])
print(data)
env = gym.make("FrozenLake-v1", is_slippery = False) #render_mode = "human"
agent = QAgent() # agent 만들기
MAXEPISODENUM = 10000
total_reward = 0
for epi in range(MAXEPISODENUM):
done = False
history = []
state = env.reset() # (0, {'prob' : 1}) <- (현재 위치, 다음 상태로 넘어갈 확률)
state = state[0]
while not done:
action = agent.select_action(state)
next_state, _, done, _, _ = env.step(action) # agent가 선택하는 action
reward = -1 # 움직일 때마다 -1
if(next_state == 15): # 15번 위치에 도달하면 리워드 10
reward = 10
elif(next_state == 5 or next_state == 7 or next_state == 11 or next_state == 12): # 구멍에 빠지면 리워드-10
reward = -10
total_reward += reward
history.append((state, action, reward, next_state))
# env.render()
state = next_state #다음 스테이트로 넘어감
agent.update_table(history) # history 업데이트
agent.decrease_eps() # 입실론값 줄이기
if(epi%1000 == 0 and epi != 0):
print(f"{epi}/{MAXEPISODENUM}")
print(total_reward/epi)
agent.show_table()
## test
env2 = gym.make("FrozenLake-v1", is_slippery = False, render_mode = "human")
agent.eps = 0.1
for epi in range(100):
done = False
history = []
s = env2.reset()
s = s[0]
while not done:
a = agent.select_action(s)
n_s, _, done, _, _ = env2.step(a)
s = n_s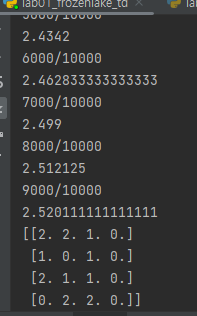
'기타 > 강화학습' 카테고리의 다른 글
| [RL 이론] - Dynamic Programming (0) | 2023.06.05 |
|---|---|
| [RL 이론] - 기초 & Markov Decision Process (0) | 2023.06.03 |
| [RL 이론] - 개념 정리 (0) | 2023.01.01 |
'기타/강화학습' Related Articles
more



Comments