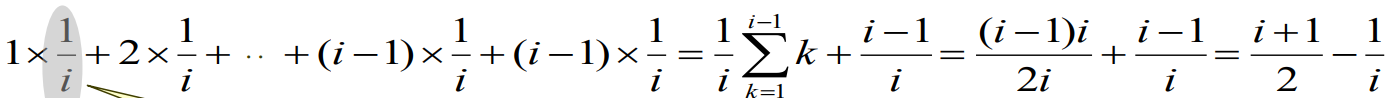- 문제 자체의 분석 ✓ 이 문제의 복잡도의 하한은 Ω(n²) => 이는 Θ(n²) 알고리즘이 반드시 존재한다는 것을 의미하는 것은 아님. Θ(n²)보다 더 좋은 알고리즘을 개발하는 것이 불가능함을 의미
복잡도 하한이 Ω(f(n))인 문제에 대해서는 복잡도가 Θ(f(n))인 알고리즘을 만들어 내는 것이 목표가 될 것이다. 문제의 복잡도 하한보다 낮은 알고리즘을 만들어 낸다는 것은 불가능하다. (물론 상수적으로 알고리즘을 향상 시키는 것은 가능하다.)
ex) 예를들어 정렬문제(sorting)를 보자.
✓ 교환정렬(Exchange sort): Θ(n²) ✓ 합병정렬(Mergesort): Θ(n lg n)
✓ 정렬문제의 계산복잡도 하한은 Ω(n lg n)
이 정렬 문제의 경우는 하한 만큼의 시간 복잡도를 가진 알고리즘을 찾은 것이기 때문에, 더 좋은 알고리즘을 개발하는 건 불가능하다.
◆ 알고리즘 분석
알고리즘을 분석하는 몇가지 지표들이 있다.
비교 횟수
지정 횟수
제자리 정렬
안정성
◆ 비교 횟수와 지정 횟수
키의 비교 횟수와 레코드의 지정(assignment) 횟수의 형식으로 알고리즘을 분석할 것이다.
ex) 예를들어 s[i]와 s[j]를 exchange하는 코드를 보자.
temp = s[i]; s[i] = s[j]; s[j] = temp
이 경우 한 번의 교환이지만, 3번의 지정문 필요
레코드의 크기가 크면레코드를 지정하는 데 걸리는 시간이 길어지므로분석에 포함하기로 한다.
◆ in-place sort (제자리 정렬)
제자리 정렬(in-place sort): 정렬을 위해 추가적으로 소요하는 저장장소가 상수인 경우
ex) 합병정렬 같은 경우 데이터 크기에 비례하는 만큼의 추가 저장장소가 필요하므로 제자리 정렬이 아니다!
◆ Stability(안정성)
같은 키 값을 갖는 데이터간의 정렬 전 순서가 정렬 후에도 유지되는 성질
그림에서 ai와 aj는 정렬 후에도 상대적인 대소관계가 같다. 이러한 성질을 갖는 정렬방법은 stable 하다고 한다. ✓ stable: insertion sort, merge sort, bubble sort - 추가적인 구현으로 stable하게 만들 수 있다. ✓ notstable: quick sort, heap sort, selection sort, exchange sort
◆ 삽입정렬 알고리즘 (Insertion Sort)
(왼쪽에서)두번째 i부터 시작. (첫번째는 j 줘야함) j가 i-1~1까지 이동할 때, S[j]가 S[i]보다 크다면 (작아질 때까지) S[j]를 오른쪽으로 한칸씩 밀어줌. (x = S[i] 저장) S[j]가S[i]보다 작은 곳에 도달했다면 S[j+1]에다 S[i]를 넣어주면서 조금씩 정렬되어감.
이미 정렬된 배열에 항목을 끼워 넣음으로써 정렬하는 알고리즘
✓ 문제: 비내림차순으로 n개의 키를 정렬 ✓ 입력: 양의 정수 n; 키의 배열 S[1..n] ✓ 출력: 비내림차순으로 정렬된 키의 배열 S[1..n]
[pseudo code]
void insertionsort(int n, keytype S[]){
index i,j;
keytype x;
for(i=2; i<=n; i++){ // i는 2~n까지
x = S[i]; // 이번 i를 x에 저장
j = i - 1; // j는 i 바로 앞에 거
while(j>0 && S[j]>x){ // j는 i-1부터 시작해서, 처음까지 내려감. 이때 S[j]가 x보다 크다면
S[j+1] = S[j]; // j를 하나씩 오른쪽으로 밀어줌.
j--;
} // 탈출했다면, -1번째(수도코드에선 0번째)로 왔거나, S[j]가 x보다 작은 지점에 도달한 것.
S[j+1] = x; // 그러면 그 위치 오른편에 x를 끼워넣으면 됨.
}
}
삽입정렬은 어느 정도 정렬된 데이터에 대해서는 빠르게 수행된다. (정렬시켜야 하는 데이터의 이동 거리가 짧아지므로)
삽입정렬은 교환정렬 보다는 항상 최소한 빠르게 수행된다고 할 수 있다.
◆ 삽입정렬 알고리즘 (Insertion Sort) 분석
단위 연산 : S[j]와 x를 비교하는 횟수
■ 최악의 경우는, 거꾸로 정렬되어있는 경우.
예를들어 5 4 3 2 1 로 정렬되어있는 경우를 생각해보자 5 4 3 2 1 =(한 번 비교)=> 4 5 3 2 1 =(2번 비교)=> 3 4 5 2 1 =(3번 비교)=> 2 3 4 5 1 =(4번 비교)=> 1 2 3 4 5 이렇게 될 것임. 이처럼 i가 주어졌을 때 i-1번의 비교가 이루어지는 경우가 최악이다.
이때 일어나는 비교 횟수는 다음과 같다.
상수 제외하고 보면n²/2만큼 비교가 일어난다고 볼 수 있음
■ 평균의 경우
i가 주어졌을 때, x가 삽입될 수 있는 장소는 i개가 있다. 이때 삽입될 장소에 대한 확률은 평균적으로 1/i라고 할 수 있다.
이제 장소에 따른 비교 횟수를 보자. i번째에 삽입할 경우 비교 횟수는 1번. i-1번째에 삽입할 경우 비교 횟수는 2번. ... 3번째에 삽입할 경우 비교 횟수는 i-2 2번째에 삽입할 경우 비교 횟수는 i-1번 1번째에 삽입할 경우 비교 횟수는 i-1번(인덱스 넘어가서 끝나서, 한번 더 비교 안함)
따라서, x를 삽입하는 데 필요한 평균 비교 횟수는 다음과 같다. (i-1)/i + Σ(i번째에 삽입될확률 * i번째에 삽입되는 경우 비교횟수)
▼ 즉 이정도가 비교 횟수라는 것.
■ 공간복잡도 분석:
- in-place sorting algorithm - 저장장소가 추가로 필요하지 않다. - 따라서 M(n) = Θ(1)
■ index 변경을 제외한, 레코드의 지정 횟수 기준 분석
void insertionsort(int n, keytype S[]){
index i,j;
keytype x;
for(i=2; i<=n; i++){
x = S[i];
j = i - 1;
while(j>0 && S[j]>x){
S[j+1] = S[j]; // 최악의 경우는 i-1번 지정
j--; // 이런건 지정으로 안침~
}
S[j+1] = x;
}
}
◆ 선택정렬 알고리즘 (selection sort)
앞자리부터 경매 시작.(i=1) 아직까지 정렬되지 않은 데이터들(j=i+1~n) 쭉 둘러보면서,가장 작은 데이터(smallest)를 선정하고, 그 자리 낙찰. (원래 그 자리 주인이랑 교체)
✓ 문제: 비내림차순으로 n개의 키를 정렬 ✓ 입력: 양의 정수 n; 키의 배열 S[1..n] ✓출력: 비내림차순으로 정렬된 키의 배열 S[1..n]
[pseudo code]
void selectionsort(int n, keytype S[]){
index i, j, smallest;
for(i=1; i<=n-1; i++){ // i는 1부터 n-1까지
smallest = i; // smallest index를 i로 초기화
for(j=i+1; j<=n; j++) // j는 i 바로 다음부터 끝까지
if (S[j]<S[smallest]) // smallest번째 데이터보다 j번째 데이터가 작다면
smallest = j; // smallest 인덱스 업데이트
exchange S[i] and S[smallest]; // 끝까지 돌고나서, i번째 위치에 갱신된 smallest번째 데이터 넣음
}
}
◆ 선택정렬 알고리즘 (selection sort) 분석
■ 비교 횟수 기준 분석
첫단계: 모든 데이터 중 가장 작은 데이터가 첫 위치 (첫 데이터와 2~마지막 데이터 비교)
두번째: 두번째~ 마지막에 있는 데이터 중 가장 작은 데이터가 두번째 위치 (두번째 데이터와 3~마지막 데이터 비교)
...
빨간 점선 부분이 비교가 일어나는 부분.
i가 첫번째일 때 비교횟수는 n-1, i가 두번째일 때 비교횟수는 n-2, …, i가 n-1번째일 때 비교 횟수는 1이 된다.
이를 모두 합하면, 1부터 n-1까지 더한
n(n-1)/2 이 비교횟수가 된다.
■ 지정 횟수 기준 분석
exchange는 총 n-1번 일어남. (이미 정렬되어 있더라도 수행됨) 한번 교환할 때 3번 지정(temp에 저장하고 바꾸기)하므로,
■ 공간복잡도 분석:
- in-place sorting algorithm
■ Stable한가?
stable하지 않다.
◆ 교환정렬 알고리즘 (exchange sort)
이번에도 앞자리부터 경매 시작.(i=1) 이번에는, 아직까지 정렬되지 않은 데이터들(j=i+1~n) 쭉 돌면서 현재 그 자리의 원소보다작은 게 나올 때마다바꿔줌. (원래 그 자리 주인이랑 교체)
✓ 문제: 비내림차순(nondecreasing order)으로 n개의 키를 정렬하라 ✓ 입력: 양의 정수 n, 키의 배열 S(첨자는 1부터 n) ✓ 출력: 키가 비내림차순으로 정렬된 배열 S
[pseudo code]
void exchangesort(int n, keytype S[ ]) {
index i,j;
for (i=1; i<=n-1; i++) // i는 1부터 n-1까지
for (j=i+1; j<=n; j++) // j는 i다음부터 n까지
if(S[j] < S[i]) // S[j]가 이번에 선택한 S[i]보다 작다면,
exchange S[i] and S[j] // 둘을 바꾼다.
}
◆ 교환정렬 알고리즘 (exchange sort) 분석
■ 비교 횟수 기준 분석
빨간 동그라미는 비교한 데이터의 양.
i가 1일때 n-1번 비교 i가 2일때 n-2번 비교 ... i가 n일 때 1번 비교 따라서 항상 총 n(n-1)/2번 비교함
■ 지정 횟수 기준 분석
한번의 exchange마다 3회의 지정이 일어난다. 최악의 경우 : 거꾸로 정렬되어있는 경우. 이 경우 모든 비교마다 exchange 발생. W(n) = 3n²/2 평균의 경우 : S[j]와 S[i]를 비교했을 때, S[j]가 더 작을 확률이 1/2라 하면 A(n) = 3n²/4
■ 공간복잡도 분석:
- in-place sorting algorithm
■ Stable 한가?
stable하지 않다.
◆ 거품정렬 알고리즘 (Bubble sort)
처음부터 아직 정렬되지 않은 데이터까지, 한번에 두개씩 비교해가면서 올라감. 둘중 왼쪽이 오른쪽보다 더 크면 바꿈. 결국 그 step에서 찾은 가장 큰 걸 가지고 그 step에서의 끝으로 가면서 뒷자리부터 채워짐
[pseudo code]
void bubblesort(int n, keytype S[ ]) {
index i,j;
for (i=n; i>=1; i--) // i는 마지막부터 처음까지 감소
for (j=2; j<=i; j++) // j는 두번째부터 i까지 증가
if(s[j-1] > s[j]) // j-1번째와 j번째를 비교해서, 앞이 더 크다면
exchange S[j-1] and S[j] //둘을 바꿈
}
◆ 거품정렬 알고리즘 (Bubble sort) 분석
■ 비교 횟수 기준 분석
i가 n일 때 i-1번 비교 i가 n-1일 때 i-1번 비교 .. i가 1일 때 i-1 = 0번 비교
항상 매번 i-1번비교한다! 따라서 i=1~n까지 Σ(i-1)을 하면,
■ 지정 횟수 기준 분석
exchange는 3번의 지정이 필요함 평균의 경우: 비교 횟수 중 exchange할 확률이 1/2라고 하면,
최악의 경우: 거꾸로 정렬되어있는 경우. 이런 경우, 비교할 때마다 exchange가 일어나는 경우이므로,
■ 공간복잡도 분석
- in-place sorting algorithm
◆ 알고리즘 별 복잡도 비교
삽입정렬은 어느 정도 정렬된 데이터에 대해서는 빠르게 수행된다.
삽입정렬은 교환정렬 보다는 항상 최소한 빠르게 수행된다고 할 수 있다.
선택정렬이 교환정렬 보다 빠른가? - 일반적으로는 선택정렬 알고리즘이 빠르다고 할 수 있다.
그러나 입력이 이미 정렬되어 있는 경우, 선택정렬은 (자신의 위치에서) 지정이 이루어지지만 교환정렬은 지정이 이루어지지 않으므로 교환정렬이 빠르다.
선택정렬이 삽입정렬 보다 빠른가? - n의 크기가 크고, 키의 크기가 큰 자료구조 일 때는 지정하는 시간이 많이 걸리므로 선택정렬 알고리즘이 더 빠르다
◆ 한번 비교하는데 최대한 하나의 역을 제거하는 정렬 알고리즘의 하한선
What is "역"?
n개의 키, 양의 정수 1, 2,…, n 가정
n개의 수가 있을 때, n! 가지의 순서 존재.
ki를 i번째 자리에 위치한 정수라고 할 때, 하나의 순열은 [k1, k2,…, kn]으로 나타낼 수 있다. - (예) [3, 1, 2]는 k1 = 3, k2 = 1, k3 = 2로 표시.
i < j와 ki > kj의 조건(앞에 있는 애가 뒤에 있는 애보다 키 값이 크다)을 만족하는 쌍(pair) (ki, kj)를 순열에 존재하는 역 (inversion)이라고 한다.(중복 제외) - (예) 순열 [3, 2, 4, 1, 6, 5]에는 5개의 역이 존재 - 역 = { (3,2), (3,1), (2,1), (4,1), (6,5) }
키를 비교만 하여 n개의 서로 다른 키를 정렬하고, 한 번 비교한 후에 최대한 하나의 역만을 제거하는 알고리즘은 최악의 경우에 최소한n(n-1)/2횟수만큼의 비교를 수행하며, 평균적으로 최소한n(n-1)/4의 비교를 수행해야 한다.
최악의 경우) 데이터가 거꾸로 정렬되어 있는 경우 순열 [n, n-1,…, 2, 1]은 n(n-1)/2개의 역을 가진다. (n기준 n-1개, n-1기준 n-2개, ... 1기준 0개(중복 제외)) 알고리즘이 한 번의 비교를 통해 하나의 역을 제거하므로, 총 비교 횟수는 n(n-1)/2
평균의 경우) 두 데이터는 역이거나, 역이 아니거나 둘중 하나임. 따라서 평균적으로 (모두 역인 경우 + 아무것도 역이 아닌 경우)/2 = n(n-1)/4개의 역을 가진다. (순열 P와 transpose P에 존재할 수 있는 역의 개수의 합은 n(n-1)/2. 평균적으로 반씩 가지고 있다고 하면 n(n-1)/4) 알고리즘이 한 번의 비교를 통해 하나의 역을 제거하므로, 총 비교 횟수는 n(n-1)/4
※ 교환, 삽입, 선택, 버블 정렬은 한번 비교할 때기껏해야 하나의 역만을 제거할 수 있으므로 시간복잡도가 최악의 경우 n(n-1)/2 , 평균적으로는 n(n-1)/4 보다 좋을 수 없다.
* 한 번 비교 후에 데이터는 실제로 이동하지는 않는 경우에도 내용적으로는 이동이 있는 것과 같으며, 역이 한 개 제거된 상태가 내부적으로 적용된다.
◆ 합병 정렬(merge sort) 알고리즘 재검토
합병 정렬은O(n lg n)이다. 얜 어떻게 이렇게 역이 빨리 줄어들까? 합병 정렬은 비교마다하나 이상의 역을 제거하므로 앞서 살펴본 교환, 삽입, 선택 정렬보다 효율적이다.
inversion이 1개 이상 줄어든다!!
◆ 빠른 정렬(quick sort) 알고리즘
문제: n개의 정수를 비내림차순으로 정렬 입력: 정수 n > 0, 크기가 n인 배열 S[1..n] 출력: 비내림차순으로 정렬된 배열 S[1..n]
슬쩍 복습~ 파티션 → 퀵소트(피봇왼쪽) →퀵소트(피봇오른쪽) 파티션은 : pivotpoint보다 작은 것/큰 것으로 배열을 분리할 수 있도록 하는 pivotpoint의 자리 찾기
[pseudo code]
void quicksort (index low, index high) {
index pivotpoint;
if (high > low) { // 적어도 데이터가 2개일 때
partition(low,high,pivotpoint); // pivotpoint의 적절한 위치를 설정해줌
quicksort(low,pivotpoint-1); // pivotpoint 왼쪽부분 quicksort
quicksort(pivotpoint+1,high); // pivotpoint 오른쪽부분 quicksort
}
}
partition()은 pivotpoint의 적절한 위치를 잡아서 레퍼런스로 돌려줌
void partition (index low, index high, index& pivotpoint){
index i, j;
keytype pivotitem;
pivotitem = S[low]; // 맨 왼쪽에 있는 데이터를 pivotitem으로 설정
j = low; // j를 맨 왼쪽 데이터 인덱스로 초기화. j는 잠재적 pivotpoint
for (i = low + 1; i <= high; i++){ // i는 젤 왼쪽 다음~ 젤 오른쪽까지
if (S[i] < pivotitem){ // S[i]가 현재 pivotitem보다 작으면,
j++; // j 하나 증가 (S[i] 들어갈 자리 하나 확보)
exchange S[i] and S[j]; //S[i] <-> S[j] 해서 S[i]를 앞쪽으로 옮김
}
} //j: pivotitem 보다 작은 그룹의 제일 우측 끝 데이터의 위치
pivotpoint = j; // 반환할 pivotpoint 인덱스 위치 설정
exchange S[low] and S[pivotpoint]; // 현재 pivotitem 값을 pivotpoint(올바른 위치임)에 넣어준다.
}
quick sort는 제자리 정렬은 아님! 재귀 호출시마다 자신의 인덱스들을 저장하고 있어야 하기 때문. 평균적으로 Θ(lg n)만큼의 추가 저장공간이 필요하다.
◆ Binary tree의 종류
완전이진트리(complete(perfect) binary tree)
✓ 트리의 내부에 있는 모든 마디에 두 개씩 자식 마디가 있는 이진 트리. ✓ 따라서 모든 leaf의깊이 (depth) d는 동일하다.
실질적인 완전이진트리(essentially complete binary tree)
✓ 깊이 d - 1까지는 완전이진트리이고, ✓ 깊이 d의 마디는 왼쪽 끝에서부터 채워진 이진트리. 배열로 나타냈을 때 실질적으로 꽉 채워진 구조
full binary tree (proper binary tree or 2-tree)
✓ 모든 노드가 0개 또는 2개의 자식노드를 갖는다
◆ Heap
힙의 성질을 만족하는 실질적인 완전이진트리
■ 힙의 성질(heap property):
어떤 node에 저장된 값은 그 node의 자식 node에 저장된 값보다 크거나 같다. – max heap 어떤 node에 저장된 값은 그 node의 자식 node에 저장된 값보다 작거나 같다. – min heap
힙은 실질적인 완전이진트리이므로, 배열만 가지고도 표현할 수 있고 해석할 수 있다.
■ 힙 구조의 특성 (maxHeap 기준)
최대값의 확인 – O(1)
최대값 제거 및 재구성 – O(lg n) - 이때 lg n은 heap에서 트리의 높이에 해당함. 젤 마지막 데이터를 루트로 올리고 heap 재구성.
데이터의 추가, 삭제, 변경 - O(lg n) - 얘네도 마찬가지로 최대 트리 높이 만큼(lg n)만 하면 재구성할 수 있다는 것
=> Heap은 최대값을 항상 유지해야 하는 Queue를 구현하는데 적합 – priority queue
■ 힙 구조의 해석 (feat. array)
❖ left child index = 2ⅹi ❖ right child index = 2ⅹi + 1 ❖ 부모 노드 인덱스 = i/2의 하한(내림)
◆ Heap - siftdown()
root 노드부터 시작해서, 나와 자식 노드 둘 중 큰 값을 비교. 내가 더 크면 냅두고, 걔가 더 크면 걔랑 자리 바꿈.
root node가 힙 성질을 만족하지 않는 경우 재구성하기! (예시는 max heap)
root 노드부터 시작해서, 자식 노드 둘 중 큰 값과 비교함. 내가 더 크면 냅두고, 자식 중 큰 애가 더 크면 걔랑 자리 바꿈. => 두 번의 비교 필요! (자식 간 비교, 나랑 자식 비교)
[pseudo code]
void siftdown(heap& H){
node parent, largerchild;
parent = root of H; //힙의 루트 노드
largerchild = parent’s child containing larger key; //자식 둘 중 큰 애
while(key at parent is smaller than key at largerchild){ //parent가 자식 중 큰 애보다 작은 동안에
exchange key at parent and key at largerchild; // 둘이 바꿈
parent = largerchild; // 다음 parent를 큰 애 자리로 설정
largerchild = parent’s child containing larger key; // 다음 largechild 선택
}
}
◆ Heap - root()
루트에서 키를 추출하고, 힙을 재구성하는 함수
[pseudo code]
keytype root(heap& H){
keytype keyout;
keyout = key at the root; //root의 데이터를 뺌
move the key at the bottom node to the root; //맨 아래 데이터를 빼서 루트로 올림
delete the bottom node; //방금 뺀 노드 삭제
siftdown(H); //맨 아래가 루트로 올라간 상태에서 트리 재구성
return keyout;
}
◆ 힙 정렬 (heap sort)
힙 정렬 아이디어
n개의 키를 이용하여 힙을 구성한다.
루트에 있는 제일 큰 값을 제거한다. → 힙 재구성
step 2를 n-1번 반복한다. (큰 값부터 하나씩 빼옴)
[pseudo code]
void heapsort(int n, heap H, keytype S[]){
makeheap(n,H); //힙 만들고
removekeys(n,H,S); //루트 하나씩 빼서 S에다 저장하기
}
// 말단부터 올라가면서 힙으로 만들기
void makeheap(int n, heap& H){
index i;
heap Hsub;
for(i=d-1; i>=0; i--) //d 는 depth를 의미
for(all subtree Hsub whose roots have depth i) //depth가 i인 애들을 root라 할때
siftdown(Hsub); //root를 기준으로 siftdown
}
void removekeys(int n, heap H, keytype S[]){
index i;
for(i=n; i>=1; i--) //오름차순 저장하기 위해 마지막부터 저장
S[i] = root(H); //루트 하나빼고 재구성하고 하나 빼고 재구성하고.. 이렇게 정렬된 S배열 완성하기
}
◆ 힙 정렬 (heap sort) - make heap 방법 비교
• 힙 정렬 방법1: 데이터가 입력되는 순서대로 매번 heap을 구성 (하나 넣을 때마다 heap up) • 힙 정렬방법2: 모든 데이터를 트리에 넣은 상태에서 한번에 heap 구성 <-이게 더 빠름
방법 1)
siftup()의 경우, 부모 노드 하나씩이랑만 비교하면 되니까 siftdown()과 다르게 한번씩만 비교하면 됨.
좀 더 자세히 분석해보자.
이런 경우 make heap을 하는 데 얼마나 걸리는지 복잡도를 분석해보자!
✓단위연산: sift-up 함수에서의 키의 비교(부모 노드와의 비교) ✓ 입력크기: 총 키의 개수 n. (n = 2^k라 가정) ✓ d를 트리의 깊이라고 하면, d = lg n.
위 트리에서, d의 깊이를 가진 마디는 정확히 하나이고 그 마디는 d개의 조상(ancestor)을 가진다.
분석을 위해, 일단 깊이가 d인 그 마디가 없다고 가정하고 키가 sift-up되는 상한값(upper bound)을 구한 후에, 깊이가 d인 마디의 키가 sift-up되는 상한값을 더해주자.
2S - S를 계산하면,
d = lg n으로 치환하고, 뒷부분을 등비급수의 합으로 표현하자. 그리고 정리하면,
이게 깊이가 d인 노드가 없는 경우의 최대 sift-up 횟수이다. 여기다가 깊이가 d인 노드의 최대 sift-up 횟수인 lg n을 더해주면, 총 sift-up횟수는 다음과 같다.
sifr-up 한번당 1회씩 비교하기 때문에, 비교 횟수도 똑같다. 따라서 방법1의 경우 O(n lg n) 시간이 필요하다!
방법 2)
일단 전부 트리에 넣음. 깊이가 d-1 노드들을 root로 생각해서 siftdown하고, 그다음엔 깊이가 d-2, d-3, ... 0인 노드들을 root로 생각해서 siftdown. (그 노드가 루트일 때 아래의 노드들은 다 힙 완성!) depth가 d-n인 노드의 경우, 최대 n번까지 밑으로 내려갈 수 있음.
이런 경우 make heap을 하는 데 얼마나 걸리는지 복잡도를 분석해보자!
✓단위연산: sift-down 함수에서의 키의 비교 ✓입력크기: 총 키의 개수 n. (n = 2^k라 가정) ✓ d를 실질적인 완전이진트리의 깊이라고 하면, d = lg n. 위 트리에서, d의 깊이를 가진 마디는 정확히 하나이고 그 마디는 d개의 조상(ancestor)을 가진다.
방법 1과 마찬가지로, 일단 깊이가d인 그 마디가 없다고 가정하고 키가 sift-down되는 상한값(upper bound)을 구한 후에, 깊이가 d인 마디의 키가 sift-down되는 상한값을 더해주자.
depth가 d-1인 경우, depth = d인 노드가 없다고 가정했기 때문에 일단 0번이라고 둠.
아까랑 똑같이 연산해주자. (2S - S 하고, d = lg n 대입하고 정리)
따라서 depth = d인 노드를 고려하지 않았을 때의 총 sift down 횟수는 다음과 같다.
이제 depth = d인 노드를 고려해보자.
이 노드의 부모 노드들에 한해서 다시 sift-down을 해줘야 한다.
β가 현 root보다 큰 최악의 경우를 생각해보면, depth = d-1인 노드를 root로 보고 sift down해서 β와 바꾸고, (1번 교환) depth = d-2인 노드를 root로 보고 sift down 해서 β와 바꾸고, (1번 교환) 마지막으로 depth = 0인 노드를 root로 보고 sift down해서 β와 바꾸면 된다. (1번 교환)
따라서 최대 lg n만큼의 sift down이 필요하다.
그럼 depth = d인 노드를 포함했을 때 총 sift down 횟수를 구해보자. n - lg n - 1 + lg n = n-1
makeheap은 2(n-1)만에 구현할 수 있는걸 알게됐음.(두번째 방법 사용) 그럼 removekeys는 어떨까?
removekeys의 분석: n = 2^k라 가정. 먼저 n = 8이고 d = lg 8 = 3인 경우, 처음 4개의 키를 제거하는데 sift되는 횟수가 최대 2회, 다음 2개의 키를 제거하는데 sift되는 횟수가 최대 1회, 그리고 마지막 2개의 키를 제거 하는 데는 sift될 수 없다. 따라서 총 sift횟수는,
Σsift횟수*sift하는 키 개수
이를 일반화하면,
가 된다. ? 그런데 한번 sift-down될 때 마다 2번씩 비교(자식간 비교, 자식과 나 비교)하므로 실제 비교횟수는
이다!!
이제 makeheap과 removekey를 통합해보자! n이 2^k일 때, 키를 비교하는 총 횟수는
을 넘지 않는다. 따라서 최악의 경우,
이 된다!!
◆ Θ(n lg n) 알고리즘의 비교
◆ 키의 비교만으로 정렬하는 경우 하한
n lg n 보다 더 빠른 정렬 알고리즘을 개발할 수 있을까?
✓ 키의 비교 횟수를 기준으로 하는 한, 더 빠른 알고리즘은 불가능. 결정트리를 통해 이를 증명해보자!
정렬알고리즘에 대한 결정트리
✓ 3개의 키 a,b,c 를 정렬하는 알고리즘의 결정트리(decision tree).
교환 정렬에서의 정렬 트리를 보자.
void exchangesort(int n, keytype S[ ]) {
index i,j;
for (i=1; i<=n-1; i++) //i는 1부터 n-1까지
for (j=i+1; j<=n; j++) // j는 i다음부터 n까지
if(S[j] < S[i]) // S[j]가 이번에 선택한 S[i]보다 작다면,
exchange S[i] and S[j] // 둘을 바꾼다.
}
그림과 같이, 이미 비교했었던 b<a를 후에 다시 비교하는 것을 알 수 있다. 즉 교환 정렬에서는 불필요한 비교가 일어남!! 주황색 부분의 경우 일어날 수 없으므로 가지침.
보조정리 7.1.
n개의 서로 다른 키를 정렬하는 결정적(deterministic ↔ stochastic)알고리즘은, 그에 상응하는 정확하게 n!개의 leaf 마디를 가진, 유효하며 가지친이진 결정트리가 존재한다
상충되는 요소들을 다 정리한 상태에서, 말단노드 개수는 n!개가 되어야 한다. (n을 정렬할 수 있는 가지수)
보조정리 7.2.
결정 트리에 의해서 수행된 최악의 경우 비교 횟수는 그 tree의 depth와 동일하다. 위 그림에서 root가 d=3인 leaf로 가려면 3번 비교해야 함.
<지금까지> 말단노드는 n!개가 나와야 하고, 적어도 몇번의 비교가 일어나야 하는지 확인하기 위해서 tree의 depth만큼 비교가 필요하다. 라는 점을 알고있다!
보조정리 7.3. 말단 노드의 개수와 트리 높이와의 관계
leaf 노드 수가 m이고, 깊이가 d이면 d >= ┌lg m┐ (lg m의 상한)이다.
위와 같이 각 부모 노드는 자식노드를 최대 2개 가진다는 점으로부터 유도하면 된다.
< 이제 합쳐보자 >
n개의 서로 다른 키를 비교만 함으로써 정렬하는 결정적 알고리즘은 최악의 경우 최소한 ┌ n lg n - 1.45n ┐ 번의 비교를 수행한다. 보조정리 7.1에 의해서, n!개의 leaf node를 가진 유효한 이진 결정트리가 존재한다. 이로부터 보조정리 7.3에 따르면 그 트리의 깊이 d >= ┌ lg n! ┐이 된다. 보조정리 7.2에 의해서, 결정트리의 최악의 경우 비교횟수는 d 와 같다. 따라서 결정트리의 최악의 경우 비교횟수 >=┌ lg n! ┐이다. 이때 lg n!는 다음과 같다.
결론적으로, 키 값의 비교를 통한 정렬은 Ω(n lg n)의 복잡도를 갖는다.
즉, n lg n 보다 더 빠른 알고리즘을 개발할 수는 없다!!
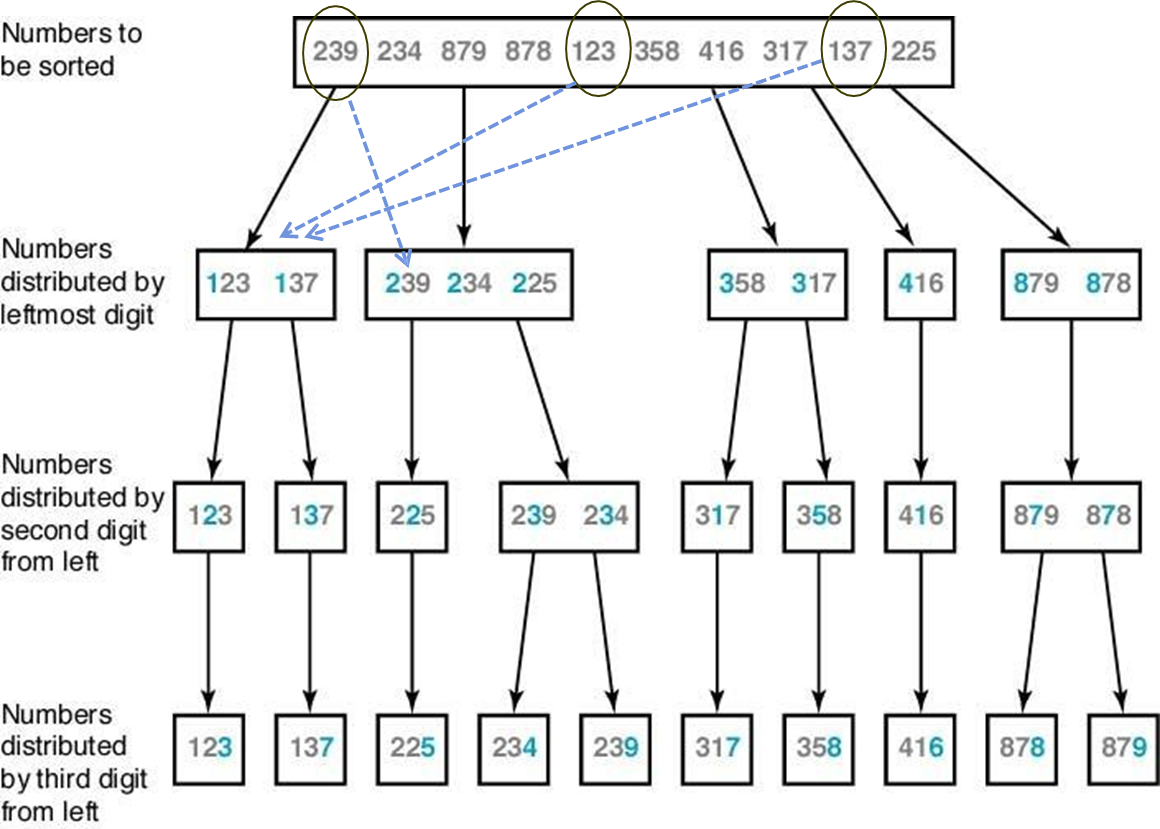
◆ 기수정렬 (radix sort)
linked list로 구현. 1의 자리부터 올라가며 한 자리씩 sort. 만약 100의자리 숫자인 경우, 100의자리와 10의자리는 같고 1의자리가 다른 두 수에 대해서 상대적인 위치가 정렬된대로 유지됨. 이런 느낌의 아이디어를 이용한 정렬.
// 특정 위치에다 데이터값을 이용해 배분
void distribute (node_pointer& masterlist, index i){
index j;
node_pointer p;
for(j=0;j<=9;j++)
list[j]=NULL;
p = masterlist;
while (p!=NULL){ //p는 계속 링크타고 내려오면서
j=p->key에서(오른쪽에서) i번째 숫자의 값;
p를 list[j]의 끝에 링크; //해당 자릿수 배열에 연결하기
p = p->link; //다음 p 확인
}
}
// list[j]에 들어가있는 list들을 하나로 묶어서 masterlist로 만드는 과정
void coalesce(node_pointer& masterlist){
index j;
masterlist = NULL;
for(j=0; j<= 9; j++)
list[j]에 있는 마디들을 masterlist의 끝에 링크
}
◆ 기수정렬 (radix sort) - 시간 복잡도 분석
단위연산: 뭉치에 수를 추가하는 연산 입력크기: 정렬하는 정수의 개수 = n, 각 정수를 이루는 디지트의 최대 개수(몇 자리수) = numdigits
모든 경우 시간복잡도 분석(10진수인 경우):
n은 distribute하는데 걸리는 시간.
10은 coalesce 하는 데 걸리는 시간. (10진수니까 배열 열자리 필요.) numdigits은 각 데이터의 자리수 위치마다 한번씩 반복이 수행되니깐.
위 식을 일반적인 경우 (k진수인 경우) 다음과 같이 표현할 수 있다.
◆ 기수정렬 (radix sort) - 공간 복잡도 분석
추가적으로 필요한 공간은, 키를 연결된 리스트(linked list)로 만드는데 필요한 공간 (link의 공간), 즉, Θ(n)
◆ 위상정렬 (Topological Sort)
✓ 정의: i 에서 j로 가는 arc가 있을 때 i가 j보다 먼저 오는 작업이라는 걸 나타내는 정렬 방법 1에서 3으로 가는 arc가 있으므로, 1이 3보다 먼저 수행하는 작업임. ✓ 물리적인 위치가 아니라 노드는 하나의 작업이라고 간주 ✓ [예] 토지구입 후 인허가 과정을 두 노드의 관계로 표시
위 관계들을 모두 만족하는 정렬된 결과는, 1-2-4-3-5가 될 수 있다. (답이 여러개 나올 수 있음)
이걸 구현하는 법! dfs에 코드를 조금 추가해서 해결할 수 있다
[pseudo code]
void dfs (vertex v){
stack S // stack은 LIFO
push(v, S) // S에 이번 v 추가
//일반적인 dfs ▽
mark[v]=visited; // 이번에 방문한 v는 visited로 설정
for each vertex w on L[v] do // v의 이웃 노드 w들에 대해서 (w는 L(v)에 저장되어있음)
if mark[w]= unvisited then // w를 방문한 적 없으면(mark[w]==unvisited)
dfs(w) //방문 ㄱㄱ
//일반적인 dfs △
print Top(S) // 재귀호출 다하고나서 젤 마지막에 넣은 애가 top에 있게 됨
Pop(S)
}
proc topological_sort()
for v=1 to n
mark[v]=unvisited //처음엔 모든 노드 unvisited로 초기화
for v=1 to n
if mark[v] unvisited //mark[v]가 unvisited 이면 dfs(v) 호출
dfs(v)
L[v]: v의 neighbors, 즉 v에서 직접 갈 수 있는 노드들의 집합 topological sort의 역순으로 출력
마지막으로 넣어야하는 것부터 Pop 될 것이므로, topological sort의 역순으로 출력됨 ㅇㅇ 위 그림 예시 형태일때, 코드 돌리면 5 3 1 4 2가 나올 것.