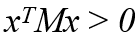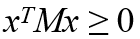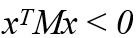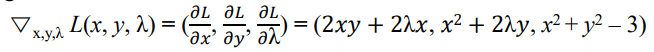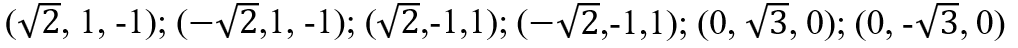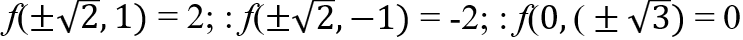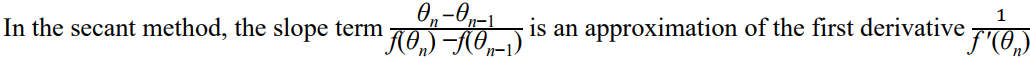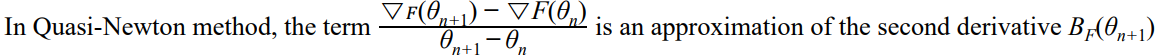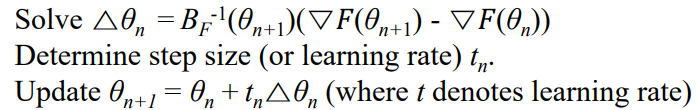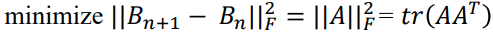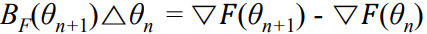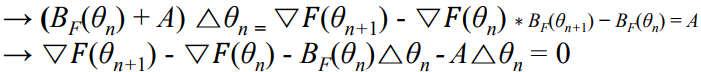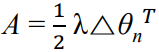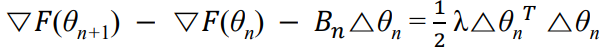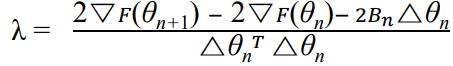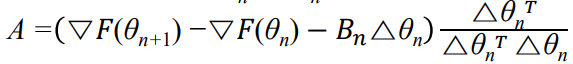Quasi-Newton method는 Hessian을 정확히 구하는 것이 아닌, Hessian의 근사를 구하는 방법이다.
2차 미분을 사용하는 Newton method의 경우 종종 수렴이 매우 빠르게 되지만, Hessian의 역함수를 구해야 하므로 큰 계산비용이 요구된다. 따라서, 많은 사람들이 Quasi-Newton Method를 선호한다.
< 대략적인 과정 >
초기 추측을 정하고, 그 지점에서의 gradient(1차 미분)을 구한다.
gradient의 변화량을 통해 Hessian을 근사한다.
근사된 Hessian을 이용해 해를 업데이트한다.
종료 조건에 도달할 때까지 반복한다.
◆ Quasi-Newton VS Newton method
< 장점 >
- 계산 비용 감소
- 빠르게 수렴함 (특히 ill-conditioned problem의 경우)
- 기존 Newton method에 비해서, 초기 추측에 덜 민감함. quadratic하게 풀리지 않더라도 제어할 수 잇따.
< 단점 >
- 덜 정확한 Hessian matrix를 사용한다.
- 어떤 문제(근사가 충분히 정확하지 않거나, well-conditioned 문제인 경우)에 있어서는 굉장히 느리게 수렴함.
◆ 기초 개념 정리
Quasi-Newton 방법을 이해하기 위한 기초 개념 몇가지부터 볼 것임.
■ ILL conditioned problem
ill-conditioned문제는 헤시안 행렬의 조건수(condition number)가 큰 경우로, 이는 최적화 과정을 수치적으로 어렵게 만듭니다. (↔well-conditioned problem: 작은 조건수를 갖는 경우)
• 행렬의 condition number란, 가장 큰 고유값과 가장 작은 고유값의 비율입니다.
• 기하학적으로 고유 벡터는 어디로 늘릴지, 고유값은 얼마나 늘릴지 라고 했다. 고유값 사이의 비율의 차이가 크다라는 건, 한쪽값이 확~ 커지는 걸의미.어떤 한 축으로 비교적 너무 많은 걸 이동하면 근사가 어려워질 수 있음 (작은 데이터에도 민감)
▶ 이러한 문제는 다양한 원인으로 발생할 수 있습니다:
• 변수의 적절한 스케일링 부재. 너무 다양한 고유값을 쓰면 차이가 커질 확률이 높음.
• 고차원 문제.
-- 대규모 신경망 훈련, 희소 신호 복구 문제 등.
• 목적 함수의 내재적 특성.
▶이를 완화(mitigate)하기 위해 다음을 사용할 수 있습니다:
• 적절한 변수 스케일링. normalize를 잘 해라
• 사전조건화. 미리 condition을 잘 정해놓기(Preconditioning)
-- 원래 문제를 수치적으로 더 좋은 성질을 갖는 동등한 문제로 변환합니다.
• ill-conditioning에 더 강건한 최적화 알고리즘 사용 (예: 신뢰영역 메소드).
-- 신뢰영역 메소드는 현재 지점을 중심으로 정의된 영역 내에서 적합한 스텝 크기와 방향을 찾는 데 초점을 맞춥니다.
-- AdaGrad, RMSProp, Adam과 같은 적응적 경사하강법은 각 매개변수에 대해 학습률을 적응적으로 조정하여 조건이 나쁘게 되는 것에 더 강건합니다.
■ Definite Matrix
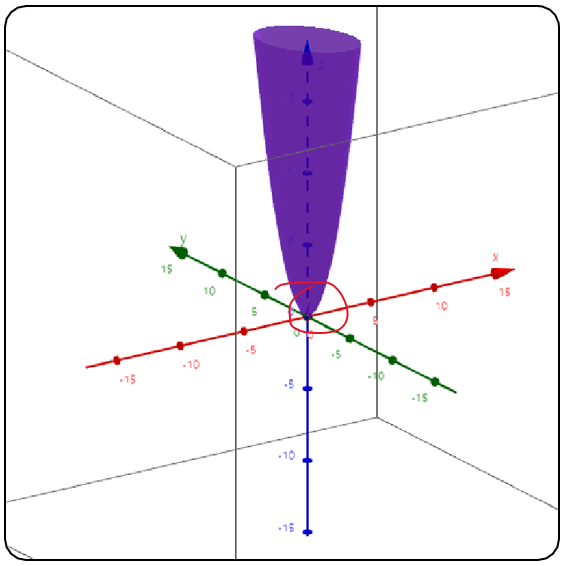
헤시안의 모든 고유값이 양수이고, 역행렬이 존재하고, 대칭인 경우 positive definite.(global minimum 존재)
M은 nxn 실수 대칭 행렬이고, 0은 n차원 0벡터라 하자.
이때 definite matrix들은 다음과 같다. (모든 x에 대해 조건이 만족하는 경우, M은 ~definite matrix이다)
positive-definite matrix , x는 0이 아닌 n차원 실수 벡터
positive-semidefinite matrix, x는 모든 n차원 실수벡터
negative-definite matrix, x는 0이 아닌 n차원 실수벡터
negative-semidefinite matrix, x는 모든 n차원 실수벡터
특히 positive-definite와 positive-semidefinite 실수 행렬은 convex optimization의 기초가 됨. (오차 최소화)
global minimum의 존재를 보장하기 때문.
함수의 헤시안 행렬이 특정 지점 p에서 positive-definite임 ↔ p 근처에서 함수는 convex(볼록)함
=> 즉, 특정 값으로 수렴하는 것이 확실하다!!
함수의 헤시안 행렬이 positive-definite인 경우, (global minimum으로의) 수렴이 보장되므로, Quasi-Newton Method를 사용할 수 있다! 즉, 반복을 하면 더 나은 방향으로 간다는 게 보장이 된 것.
definite matrix는 optimization 문제에서 중요하다. 직접 해보기 전에, 풀 수 있는지 없는지를 판단할 수 있기 때문!
ㆍpositive-definite 행렬 M의 특성
1) 모든 고유값이 양수이다,
2) 행렬은 가역이다. (det(A) != 0)
3) 행렬은 대칭이다.
positive definite 행렬은convex 함수에 해당하며, 이러한 함수는 유일한 global minimum을 가지고 있습니다.
이 특성은 최적화 알고리즘이 유일한 해에 수렴한다는 것을 보장합니다.
ㆍnegative-definite 행렬 M의 특성
1) 모든 고유값이 음수이다,
2) 행렬은 가역이다,
3) 행렬은 대칭이다.
negative-definite 행렬은concave 함수에 해당하며, 이러한 함수는 유일한 global maximum을 가지고 있습니다.
이 특성은 최적화 알고리즘이 유일한 해에 수렴한다는 것을 보장합니다.
ㆍindefinite 행렬 M의 특성
1) 행렬은양수와 음수의 고유값을 모두 가지고 있다,
2) (실수 행렬인 경우) 행렬은 대칭이다.
indefinite행렬은볼록 및 오목 영역을 모두 보이는 함수에 해당하며, 이로 인해 최적화가 더욱 어려워집니다.
예제) 간단한 2차 최적화 문제를 보자! 이 함수가 유일한 해에 수렴할까? 이 함수의 헤시안은 다음과 같다. 이제 definite-matrix인지 판단해보자. 1) 헤시안의 고유값은 5 ± √5이므로, 항상 양수이다. 2) 가역이다. 3) 헤시안은 대칭 행렬이다.(M = transpose M) => f(x,y)의 헤시안은 positive-definite matrix이므로 유일한 해(global minimum)이 존재한다!!
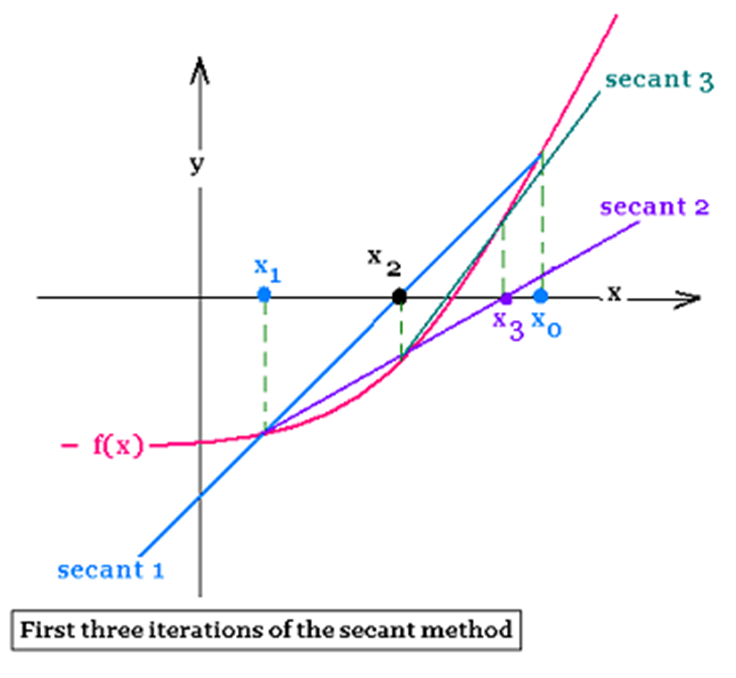
■ Secant Method
이전 두 점에서의 함수값을 기반해, 반복적으로 선형 근사해서 함수의 root를 근사하는 방법. 뉴턴 방법과 다르게 미분 대신 평균변화율을 사용함.
Secant method는 root finding알고리즘임
이전 두 점에서의 함수값을 기반해, 반복적으로 선형 근사해서 함수의 root(함수가 0이 되는 지점)를 근사하는 방법.
Secant란 마치 원에서의secant(할선)처럼, 두 점을 교차하는 직선을 의미. 그래프에서 두 점을 연결함
뉴턴 방법과 유사하지만, 미분을 사용하지 않고 대신에 평균변화율을 사용한다는 차이점이 있음.
(뉴턴은 미분해서, 도함수의 기울기 연장해서 x절편에서 다시 시작했음)
< 방법 >
1) 우선 초기 추측값 x0, x1을 선택한다.
2) x0와 x1을 잇는 할선의 기울기 m은 다음과 같다.
f(x)의 1차 미분을 대충 이걸로 추정하는 것임!! (실제 미분하지 않고 추정)
3) 이 할선이 x축과 만나는 점을 x2로 둔다.
4) f(xn)이 0이 되거나, 어느정도 0과 가까울 때까지 위 과정을 반복한다.
=> x, xn-11, xn-2 사이에 다음과 같은 관계식이 나옴!
이런 식으로 재귀적으로 반복하면서 점점 답을 찾아나가는 방법.
■ Frobenius norm
Euclidean norm이라고도 불림. matrix의 size를 추측하는 데 사용함!
다음과 같이 표현함.
이렇게 F가 붙은 경우 Frobenius norm인 것 ㅇㅇ
Frobenius norm은 tr(trace property)들과 관련이 있다.
tr(A) = A의 대각성분들의 합을 의미한다.
nxn matrix A에서 tr(A)는 다음과 같다.
AH를 A의 conjugate transpose라고 할 때, A의 Frobenius norm은 다음과 같다.
실수부일 때 AH = AT (그냥 Transpose)
허수부일 때는, 허수부에 -를 곱해주고 Transpose
※ AAT의 대각성분의 합 == A의 각 원소들 제곱의 합. 왜냐하면,
AAT의 1행 1열에는 |A11|2 ~ |A1m|2
...
AAT의 n행 m열에는 |An1|2 ~ |Anm|2 이 있을 것이기 때문. 각 행렬을 제곱해서 더한거랑 같음.
※ AAT의 대각성분의 합 == AAT의 고유값의 합 == A의 특이값 제곱의 합
■ Lagrange Multiplier
어떤 constraint가 있는 함수에서의 optimization problem(maximum 또는 minimum을 찾기)에서 사용함.
Lagrange multiplier이라고 하는 추가 변수(λ)를 사용해, 제약 조건을 목적 함수에 추가한다.
Lagrange multiplier은 제약 조건을 위반하는 경우 패널티를 주는 역할을 한다.
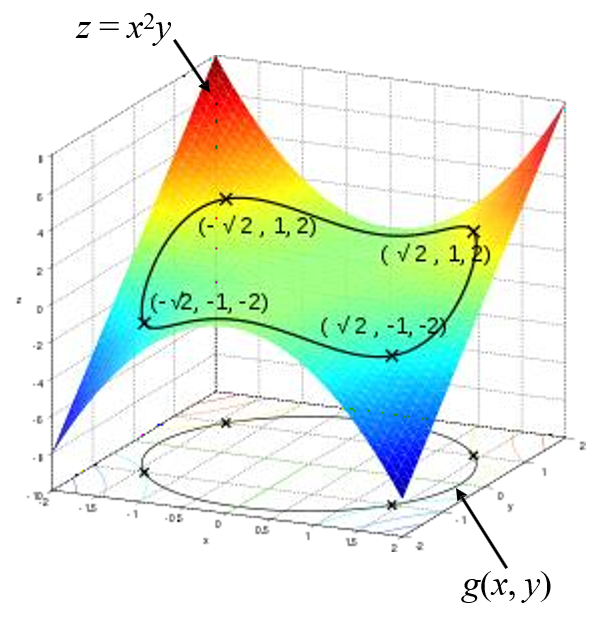
예시)
파란 점선을f(x,y)라 하고, 등고선처럼 생각해보자.
나는 지금 그림에서높은 부분을향해 나아간다고 하자
그런데 만약, '빨간색 선(g(x,y)=c) 넘어가면 안돼!'라는constraint가 걸려있다고 하자.
이 Constraint에 의해 제한될 때,나아갈수 있는 최대값(최대한 높은 부분으로 도달한 값)은 초록색 부분이다!
< 방법 >
목적 함수 f(x,y)가 있고, constraint g(x,y) = 0이 있다고 하자.
이 상황에서 f(x,y)를 maximize/minimize 하는 게 목표임!!
1) Lagrange function L(x, y, λ)를 정의하자. (λ는 Lagrange multiplier)
2) x, y, λ에 대해 각각 편미분을 하자.
3) 이 친구들(편미분한 함수들)을 다 0으로 만드는 critical point(극대값, 극소값; 도함수를 0으로 만드는 점)를 찾는다.
4) 이때 나오는 연립 방정식을 풀어서 x와 λ에 대한 optimal 값을 찾는다.
5) optimal x값을 원래 목적 함수 f(x,y)에 대입해 maximum/minimum을 찾는다.
예제) f(x,y) = x²y를 maxmize하는 문제를 풀 것이다. 이때 x,y 좌표가 반지름이 √3인 원을 벗어나지 않는 constraint가 있다고 하자. 제약 조건이 하나이기 때문에, 하나의 Lagrange multiplier λ을 사용해 Lagrange function을 정의할 수 있다. 각 원소에 대해 편미분을 하자. (gradient 계산)
이 함수들을 0으로 만드는 critical point를 찾는다.
다음 6개의 critical point를 찾을 수 있다
이 값들을 원래 목적 함수에 대입해서 최댓값을 주는 x,y를 구한다.
답은 (±√2, 1)
◆ Quasi-Newton Method - Search for extrema (극값 찾기)
기초 개념정리 끝~ 이제 Quasi-Newton method로 돌아와보자.
scalar-valued function의 maximum/minimum을 찾는다 == 그 함수의 gradient가 0이 되는 점을 찾는다는 걸 의미.
다시말해, g = ∇f일 때, vector-valued function g = 0이 되는 점을 찾는 것이 곧 scalar-valued function f의 극값(extrema)을 찾는것과 같다는 뜻. J(g) = H(f) (J(∇f) = H(f) 이므로)
Newton's method에서는
'Optimum 근처에서는 충분히 quadratic하게 수렴이 가능하다'고 추측했었다.
그리고 그 점(stationary point) 근처에서 다음과 같이 gradient와hessian을 이용해 점차 그 점을 향해 나아가도록 했었다. (1, 2차 미분 활용)
multivariate Newton optimization에서의 update function
Quasi-Newton method 에서는
헤시안 행렬의 계산 비용을 줄이기 위해, 이 식의 헤시안을 근사함으로써 업데이트를 진행할 것이다.
그럼 헤시안 행렬을 어떻게 근사하냐?
Objective function의 gradient 정보를 이용해 반복마다 업데이트되는 positive-definite matrix B를 사용해 근사.
이때 secant equation의 개념이 gradient 정보를 기반으로 헤시안 근사를 계산하는 데 큰 역할을 한다.
scalar function F(θ)가 주어졌을 때, θn 근처에서의 테일러 전개는 다음과 같다. (O(Δθ²)는 필요없으니 잘라낼 부분)
양변을 미분하면,
헤시안에 대해 정리하면,
헤시안 matrix가 θn와 θn+1 사이에서 거의 상수라고 가정하자.
BnF가 Hessian HF의 근사라 할 때, 위의 방정식은 아래와 같이 쓸 수 있다.
이 근사는 업데이트된 헤시안 근사 BF(θn+q)가 gradient의 차이 (▽F(θn+1) - ▽F(θn))와 iteration 사이의 차이 (△θ) 사이의 관계를 만족해야 함을 말합니다. 넘기면 아래처럼 익숙한 형식(▽F의 평균변화율)이 됨.
※ secant method에서처럼, 두 점에서의 정보를 사용하여 도함수를 근사한다는 점이 공통점~
secant method에서, θ 증가량 분의 f 증가량(==기울기)를 1차 미분한 도함수의 근사로써 사용했었다. Quasi-Newton method에서, θ 증가량 분의 gradient 증가량을 2차 미분한 도함수의 근사로써 사용하겠다~
◆ Quasi-Newton Method
hessian을 직접 구하지 않고, F의 gradient의 변화량을 통해서 근사해서 구함. 이때, 이전 step에서의 BF(θn) 정보를 사용하여 현재 step의 BF(θn+1)을 업데이트함
그러나 헤시안 근사치의 계산 역시 매우 비용이 많이 드는 작업입니다.
특히 변수의 수가 많거나 최적화하는 함수가 복잡한 경우에는 더 그렇습니다.
이 문제를 해결하기 위해, Quasi-Newton 방법은 이전 반복에서의 BF(θn) 정보를 사용하여 BF(θn+1)를 업데이트합니다.
B를 업데이트하는 알고리즘 몇 가지 소개.
◆ Broyden Method
위의 방법들 중, Broyden-Fletcher-Goldfarb-Shanno(BFGS) method가 가장 인기있음.
이유:
1) positive definiteness: 초기 Hessian approximation matrix B0가 positive definite이고, curvature condition (yn)TΔθ > 0을 만족하는 경우, update되는 Bn+1들도 계속 positive definite라는 걸 보장해줌.
2)convergence rate: BFGS는 다른 method들보다 convergence 특성이 높음
3) Nemerical stability: BFGS는 rule을 수학적으로 안정적으로 업데이트한다. ill-conditioned hessian approximate를 잘 하지 않는다는 뜻
그러나, 넘 어렵기 때문에 Broyden method에 대해 알아볼 것임.
이 방법은 BFGS보다는 느리게 수렴하나, 비교적 이해하기 쉬움.
이 방법을 통해서, 어떻게 Bn+1이 Bn에 의해 업데이트되는지를 볼 것임!!
< 목표 >
secant equation을 만족하면서, Bn+1과 Bn의 차이를 최소화하는 것.
둘의 Frobenius norm 차이를 최소화할 것이다.
< equation constraint >
우선, 다음과 같이 A를 정의하자.
이때 우리가 최소화해야할 것은 다음과 같다. (A의 Frobenius norm을 최소화)
앞서 구한 Quasy-Newton update function을 보자.
이를 A에 관해 표현하고, = 0 형식으로 정리해보자.
이 식이 바로 constraint를 의미한다.
< 계산 >
이제 위에서 구한 constraint를 가지고 Lagrange multiplier method를 사용해보자.